代码
请查看GitHub。直接运行文件 draft1.py 即可开始模拟,由ggui绘制,着色为密度的数值大小。
问题
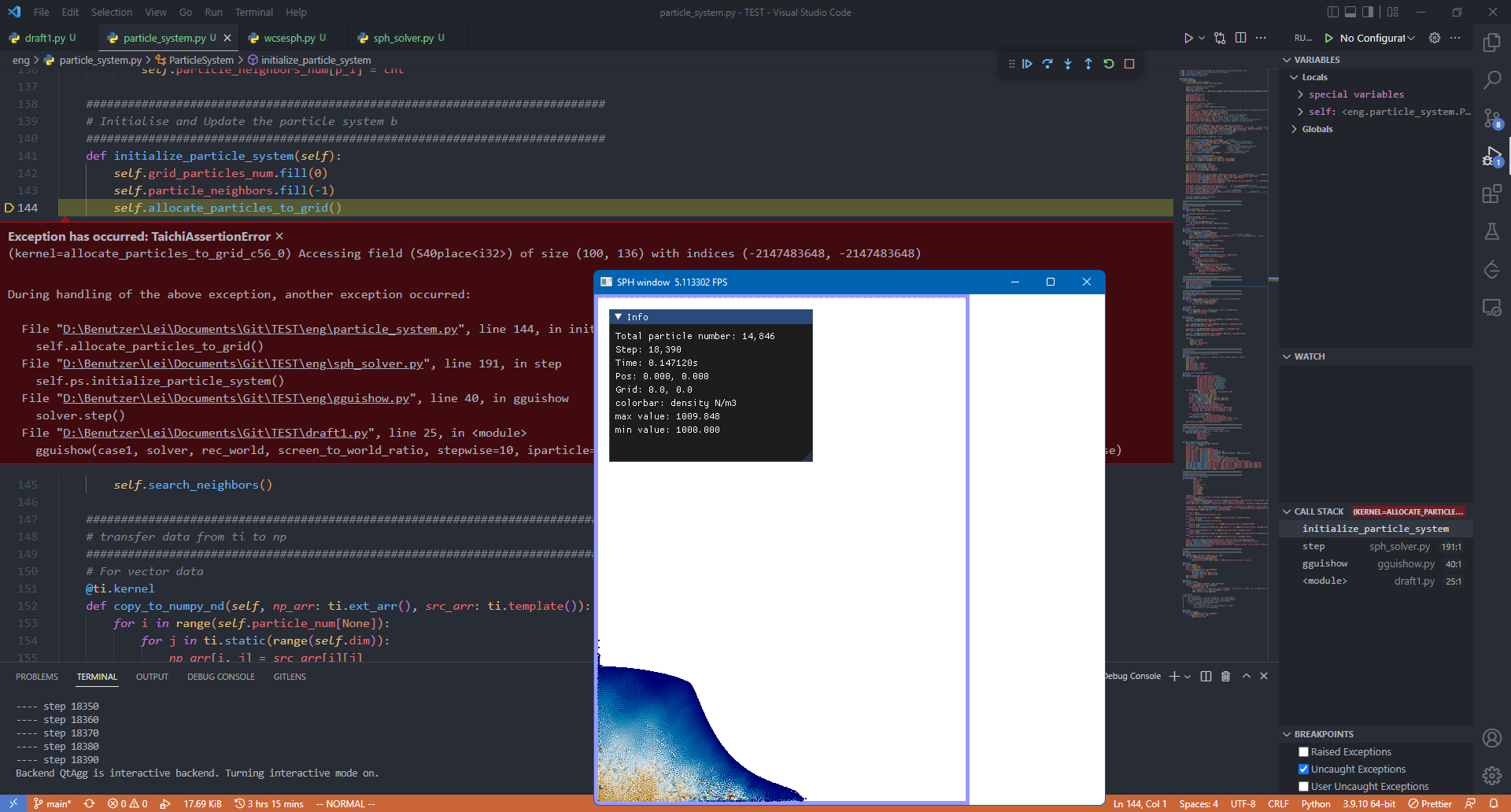
在SPH的模拟中,用CPU、debug模式,进行到某一步的时候会在“分配粒子到网格”时出现错误中断:
(kernel=allocate_particles_to_grid_c56_0) Accessing field (S40place) of size (100, 136) with indices (-2147483648, -2147483648)
这个报错应该和论坛上之前的一篇MPM相关的帖子不同?我注意到:
- 同一离散粒子半径r=0.001m下,每次模拟中断的时间都不同,但报错的size都是(100, 136);而在半径r=0.002m时报错的size为(51, 69)。
- 最后的indices (-2147483648, -2147483648) 其实就是 -2^32 。
猜测这个报错的意思是有变量的数值超过了精度范围吗?不知道这两组数具体是指什么,似乎size那一组数和模拟的边界有关?因为发现在 [0.584m*0.8m] 的模拟中,报错为 (100, 136),两数比值相似;在 [0.8m*0.8m] 的模拟中,报错为 (69, 69) 。但是为什么是这个数?后面的两个 -2^32 是什么意思?
怀疑的原因
- 核函数梯度的标准化?
经过标准化后的核函数梯度可以很好地在非对称模式下模拟一些行为。直接使用无标准化的核函数梯度可以正常进行模拟,但引入标准化矩阵后就会有这个报错。然而经过一些基本的检查,并未发现在计算这个标准化矩阵的过程中出现了什么错误。(标准化和未标准化的代码均包含在仓库里。) - 网格中或者邻域表中的粒子数量超出了100个的限制?但是当把限制改为200个时,模拟运行地会更久一些,但最终会出现同样的报错信息。
- 把WCSPH的密度计算方案改为了根据密度梯度更新。
由于直接使用核函数会导致边界尤其是自由界面附近精度不够,因此使用不会降低精度的标准化核函数梯度来更新密度。但是可能自己想的密度计算方法、每一个step中的计算顺序存在错误?
代码背景
基于Mingrui Zhang的太极图形课SPH代码,增加了ggui绘制、按colormap绘图、边界虚粒子、虚粒子赋人工速度(@Bui2008 section 4.4)、Wendland C2核函数(@Bui2021 section 2.3)、核函数梯度的标准化(@Bui2021 equation 21)、根据密度梯度更新密度(自己想的,为了避免在模拟中直接使用核函数)。
核函数梯度的标准化公式另见:

目标
使用标准化的核函数梯度模拟水的行为。