我有个渲染程序,是需要渲染一万多张图,测速下来发现taichi在渲染前500多张图的时候非常快,每张大概在3e-5s左右,但是过了五百左右就开始降速,变成0.01,0.02左右,很奇怪,不知道有没有大神遇到过类似的问题?或者taichi有什么释放gpu占用的操作我不知道?
我也遇到了类似的问题,我的一个kernel 在for循环的前15次基本上秒跑完,后面就很慢了,不知道为何,期待有人能回复一下
如下图所示:
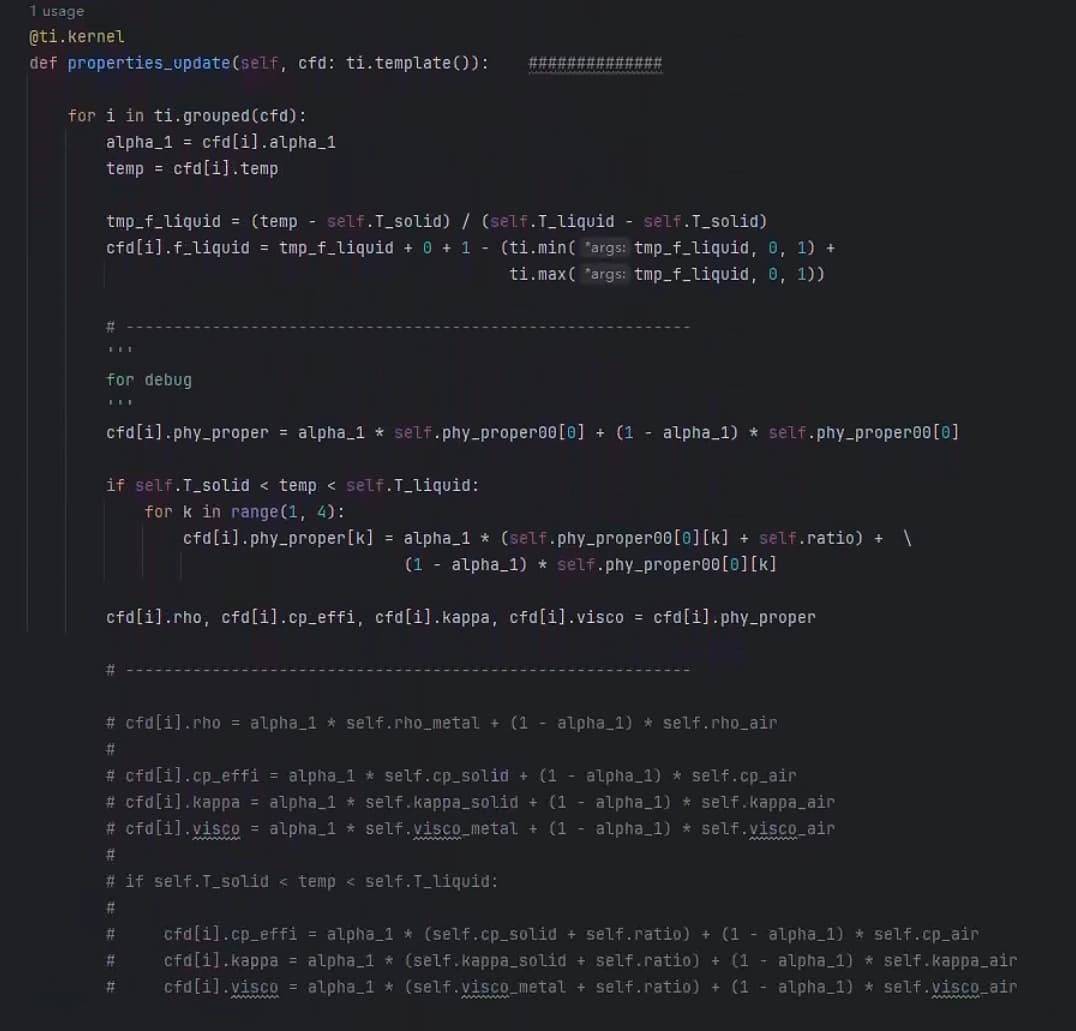
图一为kernel块:其properties 赋值用了两种方法,并以#-------------------------- 分开。其实这个赋值很简单
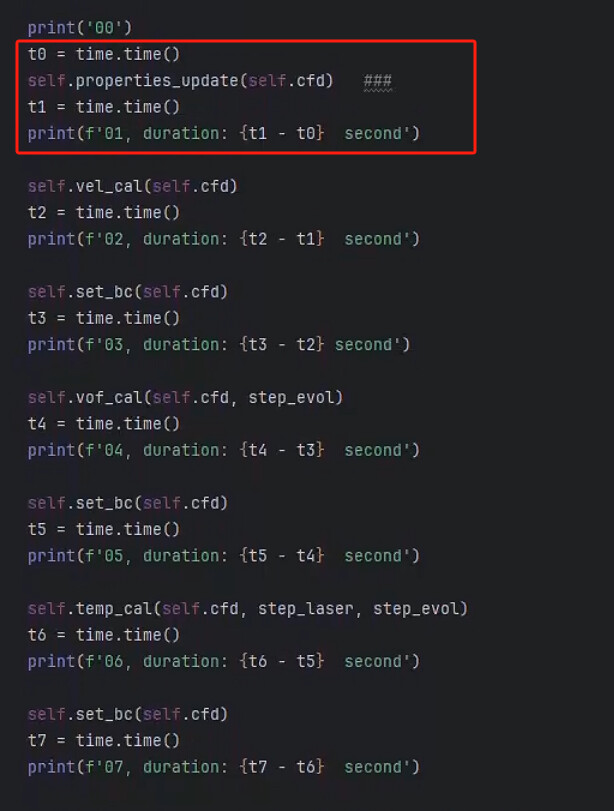
图二为不同的kernel进行运行时间观察对比。
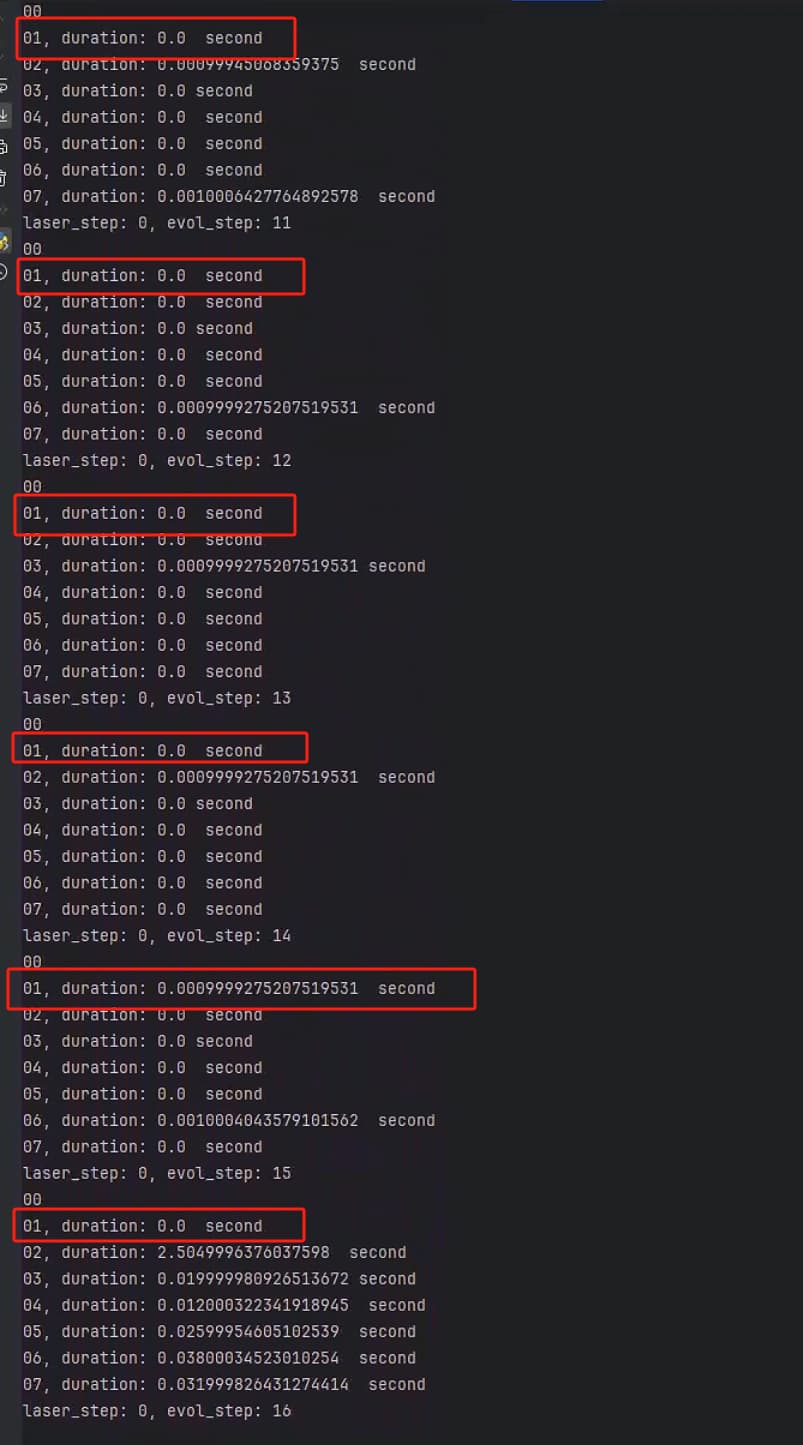
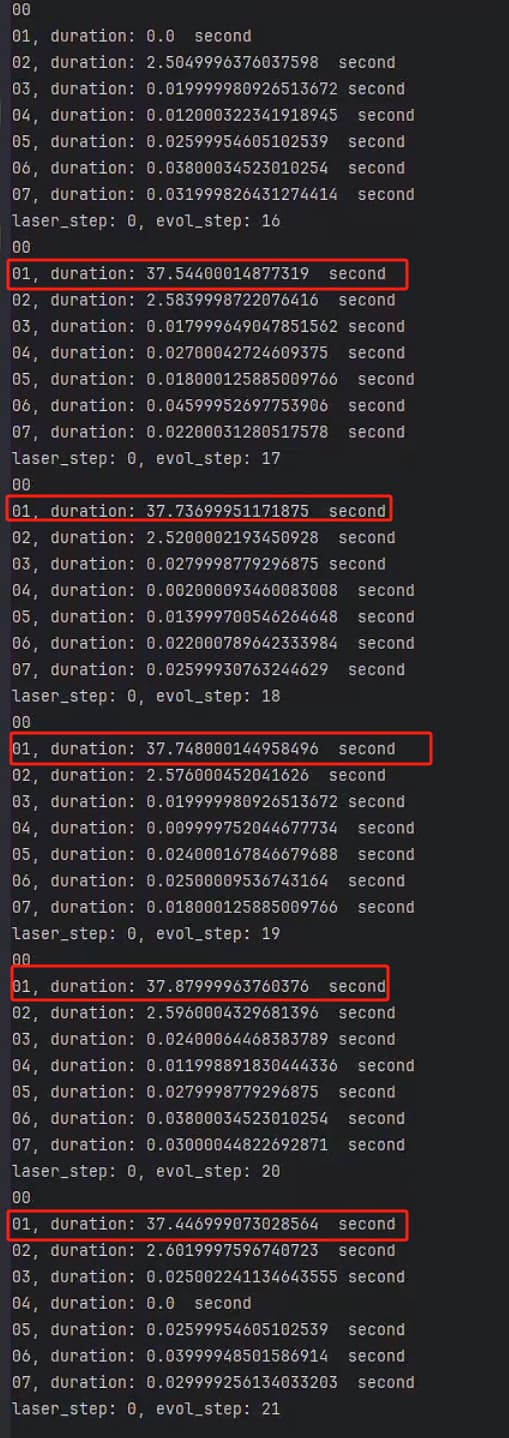
图三和图四分别为不同for循环步骤的时间对比。
从图三和图四可以看出,在for循环前15步左右,所有的kernel块运行时间大约为0秒(除了第一次编译的时间),但16次后的for循环,properties_update就猛增到37秒,其他更复杂的kernel没有什么变化。
请问在properties_update 这么简单的赋值kernel中出现这种 减速,是因为什么呢?
初步想到的一个解决办法是先 to_numpy(),在 python scope中赋值,再 from_numpy()到 taichi scope中,但不确定是否可行。