Krhkk
#1
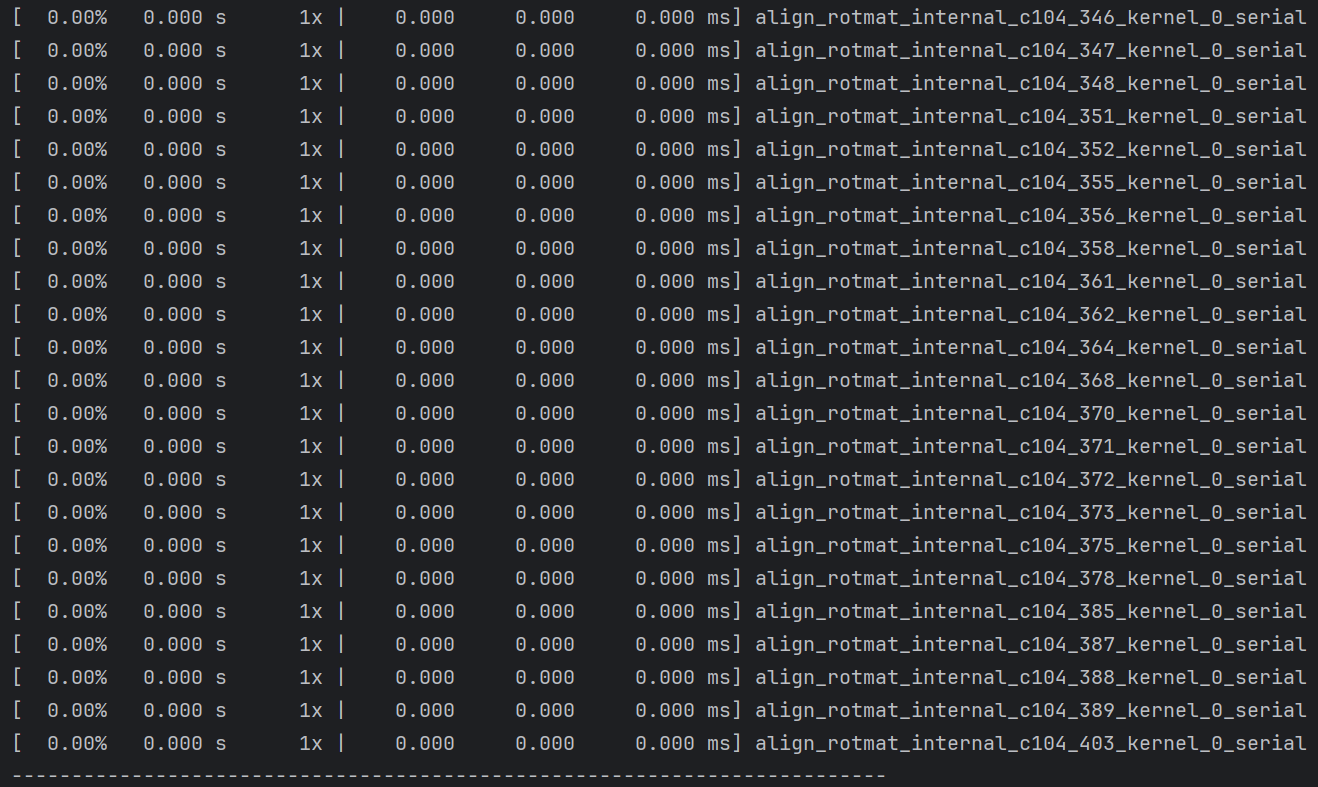
不知道为什么这个kernel内的函数没有被自动并行化执行
这个代码看起来应该能并行啊
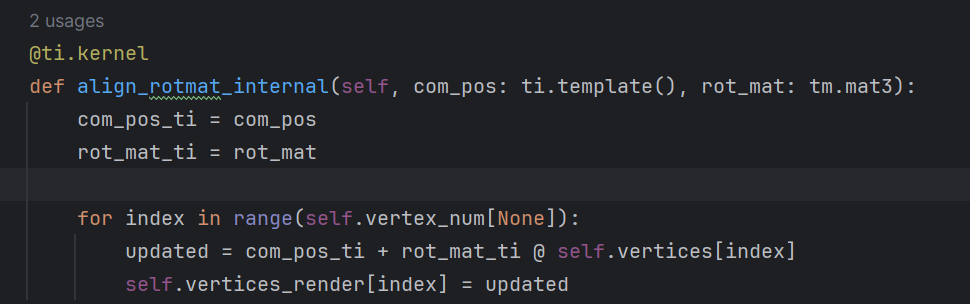
这里的self.vertices_render是一个field变量吗?
也有可能是在ti.init里要求串行了?
Krhkk
#3
是一个field变量,我尝试了
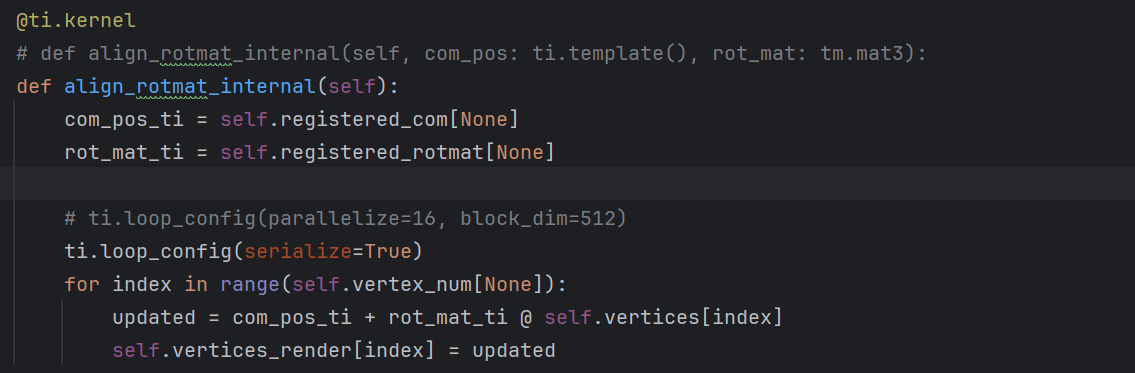
ti.loop_config(parallelize=16, block_dim=512) 以及
ti.loop_config(serialize=True);
但是他们在cpu和cuda,serialize=True或者parallelize的运行速度一样,也可能是我写的不太好吧。
不使用ti.template(),直接用ti.types.Vector()速度提升倒是挺明显的