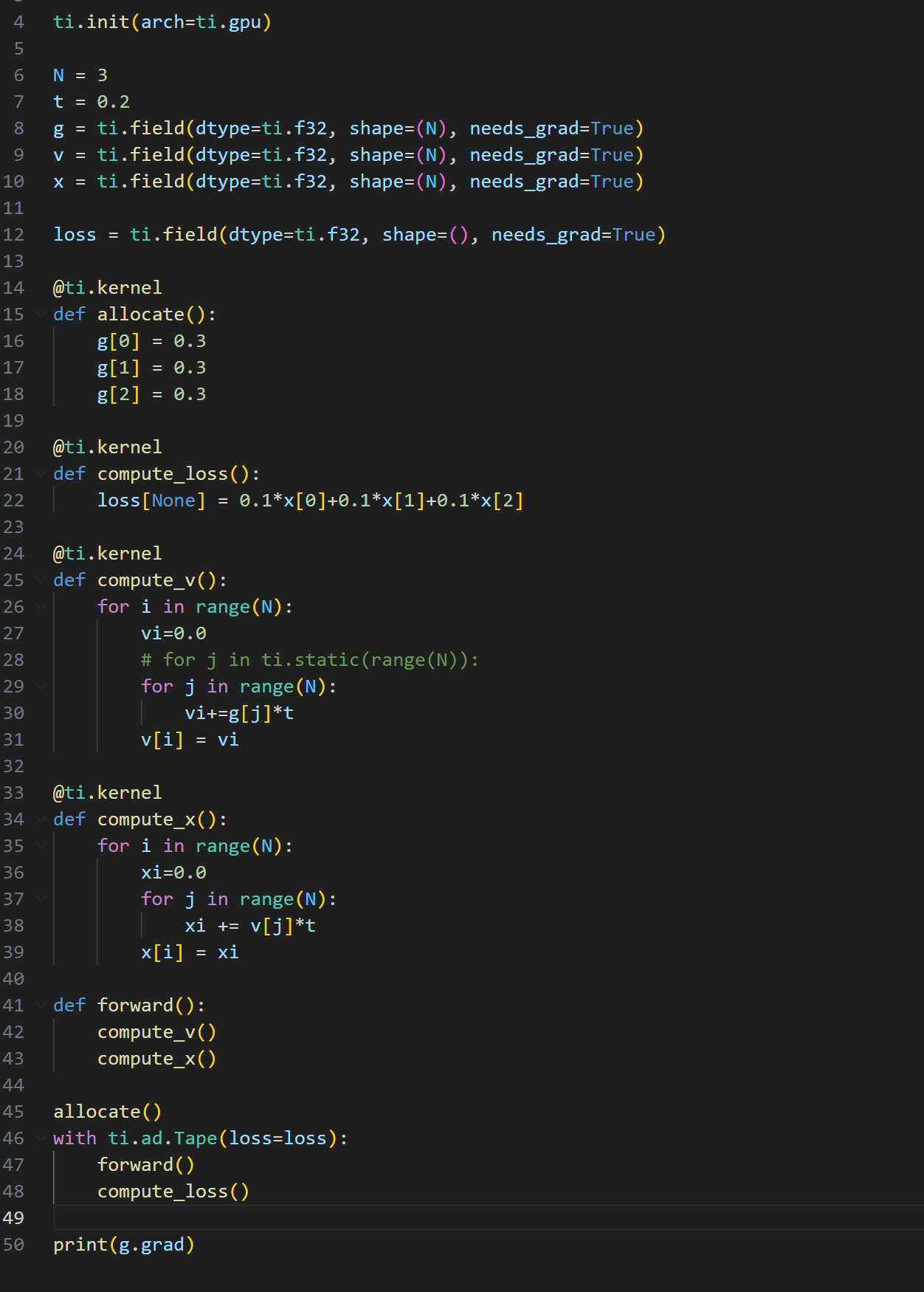
import taichi as ti
import numpy as np
ti.init(arch=ti.gpu)
N = 3
t = 0.2
g = ti.field(dtype=ti.f32, shape=(N), needs_grad=True)
v = ti.field(dtype=ti.f32, shape=(N), needs_grad=True)
x = ti.field(dtype=ti.f32, shape=(N), needs_grad=True)
loss = ti.field(dtype=ti.f32, shape=(), needs_grad=True)
@ti.kernel
def allocate():
g[0] = 0.3
g[1] = 0.3
g[2] = 0.3
@ti.kernel
def compute_loss():
loss[None] = 0.1x[0]+0.1x[1]+0.1*x[2]
@ti.kernel
def compute_v():
for i in range(N):
vi=0.0
# for j in ti.static(range(N)):
for j in range(N):
vi+=g[j]*t
v[i] = vi
@ti.kernel
def compute_x():
for i in range(N):
xi=0.0
for j in range(N):
xi += v[j]*t
x[i] = xi
def forward():
compute_v()
compute_x()
allocate()
with ti.ad.Tape(loss=loss):
forward()
compute_loss()
print(g.grad)
以上是测试代码,损失函数是关于自变量g的一个计算时间复杂度为O(n^2)的函数。如果使用自动微分,计算v(compute_v())时需要把内层for循环展开计算,否则计算的导数是错误的。
不知道是我的写法有问题,还是taichi对于累加运算一定要用ti.static展开for循环。我看到官方的diffmpm.py涉及到累加操作时也用到了ti.static,但是展开的次数很少所以没有影响计算效率。在我们的例子中,N的规模比较大,展开的计算量是无法承受的。