我想在taichi中实现如下功能
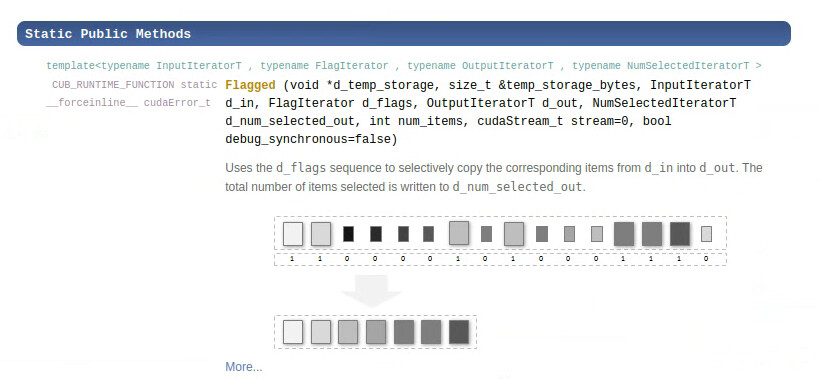
但不知道该算法如何高效地实现,不知各位大佬有什么方法可以实现
import taichi as ti
import numpy as np
ti.init()
n = 65536
dat = ti.field(shape=n, dtype=ti.f32)
out = ti.field(shape=n, dtype=ti.f32)
out_n = ti.field(shape=(), dtype=ti.i32)
@ti.kernel
def init():
for i in dat:
dat[i] = ti.random()
@ti.kernel
def filterabove(val: ti.f32):
for i in dat:
if dat[i] > val:
out[ti.atomic_add(out_n[None], 1)] = dat[i]
init()
filterabove(0.5)
print(dat.to_numpy())
print(out.to_numpy()[:out_n[None]])
用原子操作的速度太慢了,我对计算效率要求比较高,因此需要一个不用原子操作的方法
你是什么后端?我实测cuda后端,完全没有性能问题(比cpu单线程快200倍),这是因为最新版的cuda已经会自动检测到这种scan类型的atomic_add并优化,不需要用户操心。
import tqdm
import multiprocessing as mp
def teston(arch):
import taichi as ti
ti.init(arch=getattr(ti, arch), cpu_max_num_threads=1)
n = 32*1024*1024
dat = ti.field(shape=n, dtype=ti.f32)
out = ti.field(shape=n, dtype=ti.f32)
out_n = ti.field(shape=(), dtype=ti.i32)
@ti.kernel
def init():
for i in dat:
dat[i] = ti.random()
@ti.kernel
def filterabove(val: ti.f32, arch: ti.template()):
if ti.static(arch == 'cpu'):
out_n[None] = 0
for i in dat:
if dat[i] > val:
x = out_n[None]
out[x] = dat[i]
out_n[None] = x + 1
else:
out_n[None] = 0
for i in dat:
if dat[i] > val:
out[ti.atomic_add(out_n[None], 1)] = dat[i]
init()
filterabove(0.5, arch)
for _ in tqdm.trange(30 if arch == 'cpu' else 1000, desc=repr(arch)):
filterabove(0.5, arch)
out_n[None]
print(dat.to_numpy())
print(out.to_numpy()[:out_n[None]])
p = mp.Process(target=teston, args=['cpu'])
p.start()
p.join()
p = mp.Process(target=teston, args=['vulkan'])
p.start()
p.join()
p = mp.Process(target=teston, args=['opengl'])
p.start()
p.join()
p = mp.Process(target=teston, args=['cuda'])
p.start()
p.join()
[Taichi] version 1.6.0, llvm 15.0.4, commit f1c6fbbd,
linux, python 3.11.3
[Taichi] Starting on arch=x64
'cpu': 100%|██████████| 30/30 [00:04<00:00, 6.54it/s]
[0.09025651 0.7161016 0.87153447 ... 0.44793302 0.661
2071 0.07298928]
[0.7161016 0.87153447 0.7756159 ... 0.5927665 0.698
65537 0.6612071 ]
[Taichi] version 1.6.0, llvm 15.0.4, commit f1c6fbbd,
linux, python 3.11.3
[Taichi] Starting on arch=vulkan
'vulkan': 100%|██| 1000/1000 [00:02<00:00, 430.51it/s]
[0.78194785 0.59933853 0.48945174 ... 0.47105327 0.168
53262 0.761277 ]
[0.85351384 0.8995054 0.84267783 ... 0.6351333 0.749
64887 0.63610464]
[Taichi] version 1.6.0, llvm 15.0.4, commit f1c6fbbd,
linux, python 3.11.3
[Taichi] Starting on arch=opengl
'opengl': 100%|██| 1000/1000 [00:01<00:00, 711.19it/s]
[0.78194785 0.59933853 0.48945174 ... 0.7318162 0.502
35933 0.6785292 ]
[0.5266393 0.8749362 0.86646426 ... 0.6383867 0.525
35343 0.99119294]
[Taichi] version 1.6.0, llvm 15.0.4, commit f1c6fbbd,
linux, python 3.11.3
[Taichi] Starting on arch=cuda
'cuda': 100%|████| 1000/1000 [00:01<00:00, 997.95it/s]
[0.09025651 0.6511998 0.39262128 ... 0.56197876 0.675
2315 0.9838522 ]
[0.7408985 0.5477631 0.7248089 ... 0.89632535 0.638
02356 0.55608183]
你看,性能没有问题,现在CUDA都会自动优化掉这类特殊的atomic操作的。
好的谢谢