import taichi as ti
import numpy as np
import time
ti.init(arch=ti.gpu, default_fp=ti.f32)
res = 512
dt = 2e-4
substep = 100 #50
m_g = 128
n_grid = m_g*m_g
n_particle = n_grid * 4 # 9000
length = 10.0 # 1
dx = length/m_g
inv_dx = 1/dx
solid boundary
boundary_width = 2
eps = 1e-5
p_rho = 1
p_vol = (dx*0.5)**2
p_mass = p_vol * p_rho
g = -9.8
E = 400
cell-centered grid
momentum
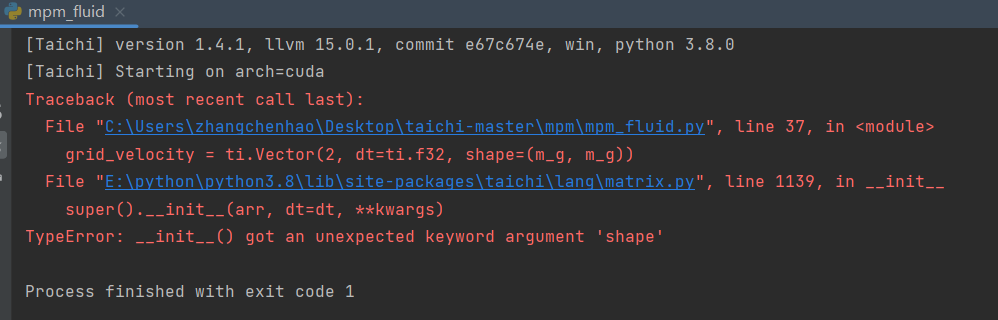
grid_velocity = ti.Vector(2, dt=ti.f32, shape=(m_g, m_g))
mass
grid_weight = ti.var(dt=ti.f32, shape=(m_g, m_g))
particle_velocity = ti.Vector(2, dt=ti.f32, shape=n_particle)
particle_position = ti.Vector(2, dt=ti.f32, shape=n_particle)
particle_C = ti.Matrix(2, 2, dt=ti.f32, shape=n_particle)
particle_J = ti.var(dt=ti.f32, shape=n_particle)
#TODO
@ti.kernel
def init_particle():
for i in particle_position:
particle_position[i] = (ti.Vector([ti.random(), ti.random()])*0.5 + 0.05) * length
particle_velocity[i] = ti.Vector([0.0, -1.0])
particle_J[i] = 1.0
@ti.kernel
def init_step():
for k in ti.grouped(grid_velocity):
grid_velocity[k] = ti.Vector([0.0, 0.0])
grid_weight[k] = 0.0
@ti.kernel
def particle_to_grid():
for k in particle_position:
p = particle_position[k]
grid = p * inv_dx
base = int(grid-0.5)
fx = grid - base
w = [0.5*(1.5-fx)**2, 0.75-(fx-1)**2, 0.5*(fx-0.5)**2] # B-spline
stress = -dt * 4 * E * p_vol * (particle_J[k] - 1) * (inv_dx**2)
affine = ti.Matrix([[stress, 0], [0, stress]]) + p_mass * particle_C[k]
for i in ti.static(range(3)):
for j in ti.static(range(3)):
offset = ti.Vector([i, j])
weight = w[i][0] * w[j][1]
dpos = (offset - fx) * dx
grid_velocity[base + offset] += weight * (p_mass * particle_velocity[k] + affine @ dpos)
grid_weight [base + offset] += weight * p_mass
@ti.kernel
def grid_normalization():
for k in ti.grouped(grid_velocity):
weight = grid_weight[k]
if weight > 0:
grid_velocity[k] = grid_velocity[k] / weight
@ti.kernel
def apply_gravity():
for k in ti.grouped(grid_velocity):
grid_velocity[k].y += g * dt
@ti.kernel
def handle_boundary():
for i, j in grid_velocity:
if i < boundary_width and grid_velocity[i, j].x < 0:
grid_velocity[i, j].x = 0
if i > m_g - 1 - boundary_width and grid_velocity[i, j].x > 0:
grid_velocity[i, j].x = 0
if j < boundary_width and grid_velocity[i, j].y < 0:
grid_velocity[i, j].y = 0
if j > m_g - 1 - boundary_width and grid_velocity[i, j].y > 0:
grid_velocity[i, j].y = 0
@ti.kernel
def grid_to_particle():
for k in particle_position:
p = particle_position[k]
grid = p * inv_dx
base = int(grid-0.5)
fx = grid - base
w = [0.5*(1.5-fx)**2, 0.75-(fx-1)**2, 0.5*(fx-0.5)**2] # B-spline
new_v = ti.Vector([0.0, 0.0])
new_C = ti.Matrix([[0.0, 0.0], [0.0, 0.0]])
for i in ti.static(range(3)):
for j in ti.static(range(3)):
offset = ti.Vector([i, j])
weight = w[i][0] * w[j][1]
dpos = (offset - fx) * dx
new_v += weight * grid_velocity[base + offset]
new_C += 4 * weight * grid_velocity[base + offset].outer_product(dpos) * (inv_dx**2)
particle_velocity[k] = new_v
particle_position[k] += particle_velocity[k] * dt
particle_J[k] *= 1 + new_C.trace() * dt
particle_C[k] = new_C
def step():
init_step()
particle_to_grid()
grid_normalization()
apply_gravity()
handle_boundary()
grid_to_particle()
##############################
init_particle()
gui = ti.GUI(“MPM Fluid”, (res, res))
result_dir = “./result”
video_manager = ti.VideoManager(output_dir=result_dir, framerate=30, automatic_build=False)
for frame in range(450):
gui.clear(0xFFFFFF)
# gui.clear(0x555555)
for i in range(substep):
step()
gui.circles(particle_position.to_numpy() / length, radius=0.8, color=0x3399FF)
gui.text('MPM', pos=(0.05, 0.95), color=0x0)
# video_manager.write_frame(gui.get_image())
gui.show()
版本如下:
[Taichi] version 1.4.1, llvm 15.0.1, commit e67c674e, win, python 3.8.0