我们尝试运行了taichi-nerf。按照readme的解说,进行了安装。
安装运行环境为
RTX 6000 Ada, AMD EYPC 7763, 512GiB RAM
Ubuntu 20.04.6 LTS,Python 3.11.2,taichi-nightly 1.6.0.post20230402, torch 2.0.0
ti gallery运行正常,
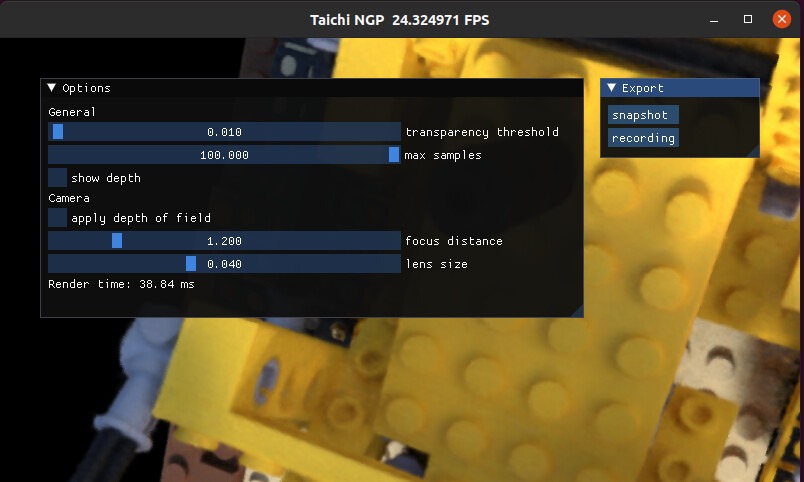
taichi-nerf能够正常出图,比如Lego。
然而,运行速度经过测试,单帧仅推理耗时大致和同环境下安装的torch-ngp一致,远差于预期的和instant-ngp相当:
Taichi:
No --half2_opt: 94ms
With --half2_opt: 82ms
No --half2_opt and torch.set_float32_matmul_precision(‘medium’): 98ms
Torch-ngp:75ms
Instant-ngp:22ms
分辨率为800x800,手动控制机位大致一致,同时同系统中有其他应用程序,但是没有占用这张卡,也没有跑满cpu/内存。因此速度可能存在偏差,大致认为taichi-nerf和torch-ngp速度一致,比instant-ngp差了4倍。
细节详见https://cxr7ii2pbr.feishu.cn/docx/EBmzdP2Pco4C7sxMb2IcOvUHngf
这个速度是否正常?什么地方可能会出现问题导致运行速度下降到torch-ngp水平?如何解决这个速度问题,假如这是个问题?
尤其是注意到在文章中提到,taichi-nerf的推理速度和cuda实现类似。谢谢
是否可能是因为taichi在当前环境下没能加速?
mzhang
#2
Hi @Asxcvbn , 感谢关注taichi-nerf。
关于训练和推理的性能,taichi-nerf里更关注的是训练的pipeline,如果想要更快的推理速度,有一个纯推理的taichi ngp renderer: GitHub - Linyou/taichi-ngp-renderer: An Instants-NGP renderer that has been implemented using Taichi , 里面有一个convert.py 文件可以把taichi-nerf训练好的模型接进renderer
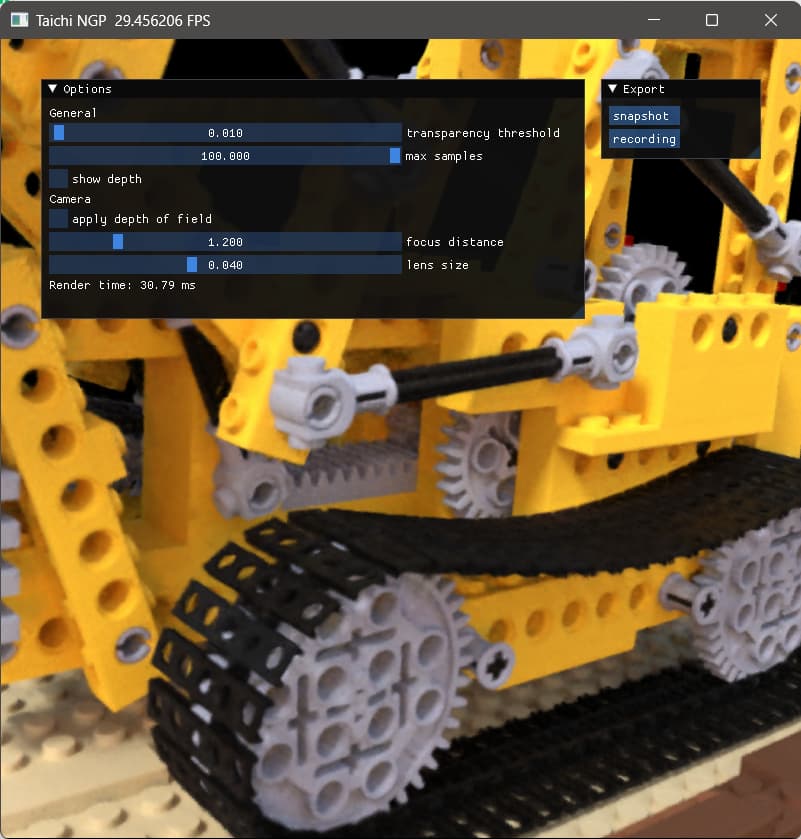
另外,我们在RTX3090和RTX4090上用taichi-ngp-render重新做了个验证:
-
RTX3090 (~40 ms)
-
RTX4090 (~30 ms)
rtx 6000 Ada理论性能应该比4090还要强,我们感觉应该还能比~30ms再快些,不过因为我们没有6000 ada的卡,可能要麻烦你们那边再用taichi-ngp-renderer再试一试?
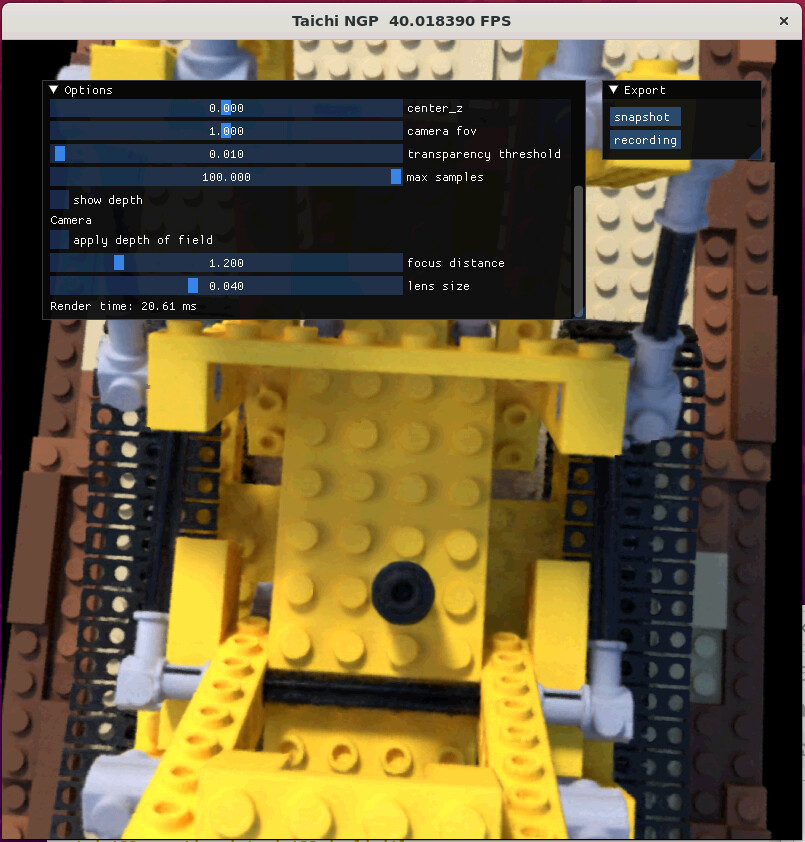
感谢 @mzhang 回复和帮助。 我们也尝试了taichi-ngp-render, 在repo自带的预训练的lego数据集中,放在rtx6000ada能够达到20ms,这个速度还是很棒的。
不过在训练自定义数据集的时候,我们注意到taichi-ngp-renderer的converter.py似乎不太能够对taichi-nerf的ckpt进行转换:taichi-ngp-render的readme要求使用ngp_pl训练的模型来转换,converter.py也要求ckpt里面包括"K", ‘model.rgb_net.params’ 等项,而这些项目在taichi-nerf的ckpt中并不存在。如果
convert.py 文件可以把taichi-nerf训练好的模型接进renderer
是预期的目标的话,也许目前这个包还没做到?
我们会尝试把利用ngp_pl训练的模型来转换成taichi-ngp-renderer的数据类型。