我运行了一个简单的程序,cuda后端时snode_reader的耗时非常多,请问我该怎样找出这里snode reader操作对应程序中的部分? 如果运行cpu后端,则snode_reader几乎不耗时
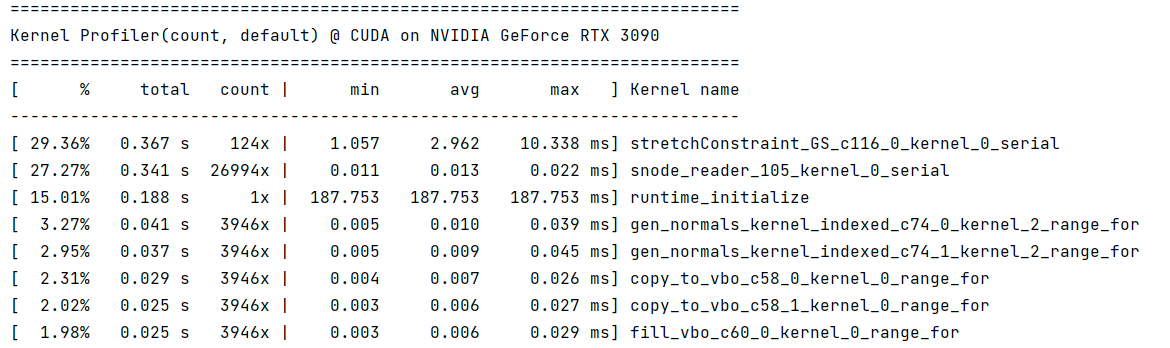
是不是程序里有大量在python scope访问field的操作呢? 这种操作需要launch kernel即snode_reader导致效率受影响,可以尽量在Taichi scope,即kernel内访问field。
哈哈,确实有个函数忘了写成kernel函数了。里面有不少对field的访问
1 个赞