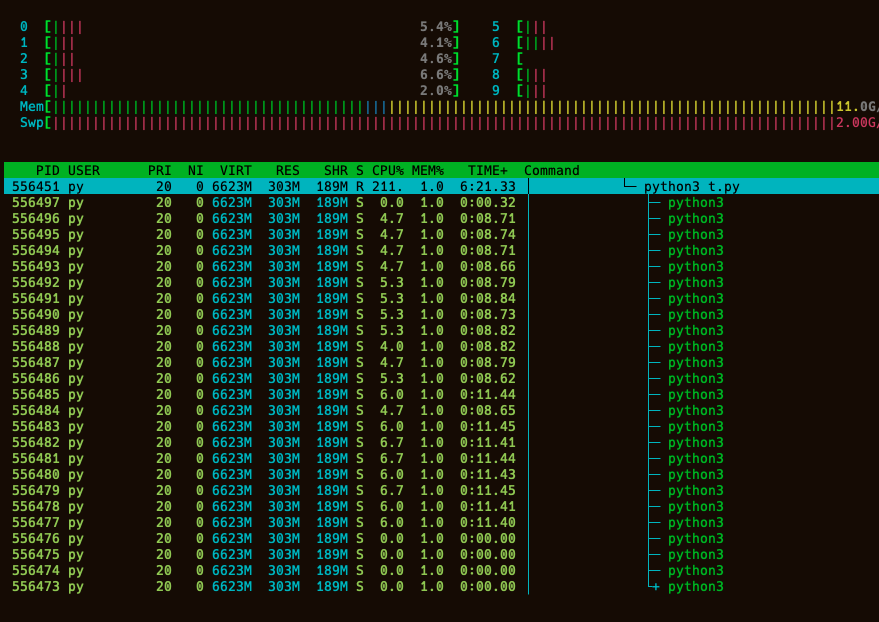
我想求一个大矩阵的binary rank 并取平均。但是没有办法并行的求
代码如下
import taichi as ti
ti.init(arch=ti.cpu)
num_site = 1024
num_copy = 128
mat = ti.field(dtype=ti.u8, shape=(num_site, num_site))
mat_copy = ti.field(dtype=ti.u8, shape=(num_copy, num_site, num_site))
rank_lis = ti.field(dtype=ti.u8, shape=num_copy)
@ti.kernel
def average_rank():
mat_eval()
for i in range(num_copy):
rank_sum(i)
@ti.func
def mat_eval():
for i, j in mat:
mat[i, j] = ti.random(dtype=ti.i32) % 2
for i, j, k in mat_copy:
mat_copy[i, j, k] = mat[j, k]
for i in rank_lis:
rank_lis[i] = 0
@ti.func
def rank_sum(copy_idx: ti.i32):
ti.loop_config(serialize=True)
for i in range(num_site):
piv_j = -1
for j in range(num_site):
if mat_copy[copy_idx, i, j] == 1:
piv_j = j
rank_lis[copy_idx] += 1
break
if piv_j >= 0:
for ii in range(num_site):
if i == ii or mat_copy[copy_idx, ii, piv_j] == 0:
continue
for jj in range(num_site):
mat_copy[copy_idx, ii, jj] ^= mat_copy[copy_idx, i, jj]
average_rank()
print(rank_lis)