LoYoT
#1
Taichi 实现 Instant NGP 的渲染
Instant NGP 是加速 NeRF 训练和渲染的新方法 (SIGGRAPH 2022)
本项目的主要内容:
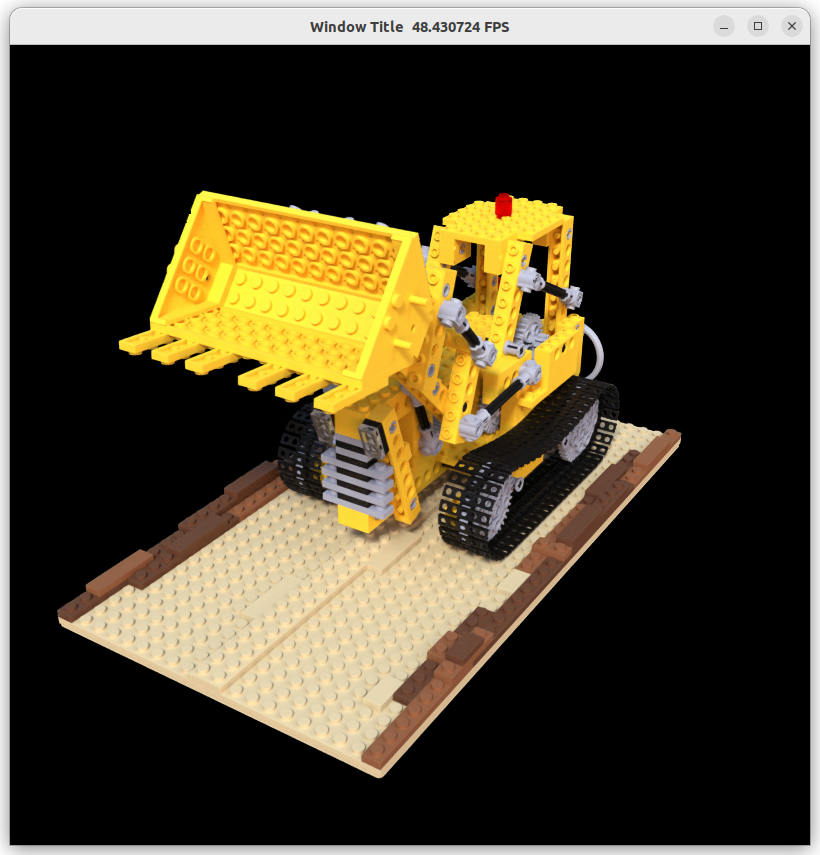
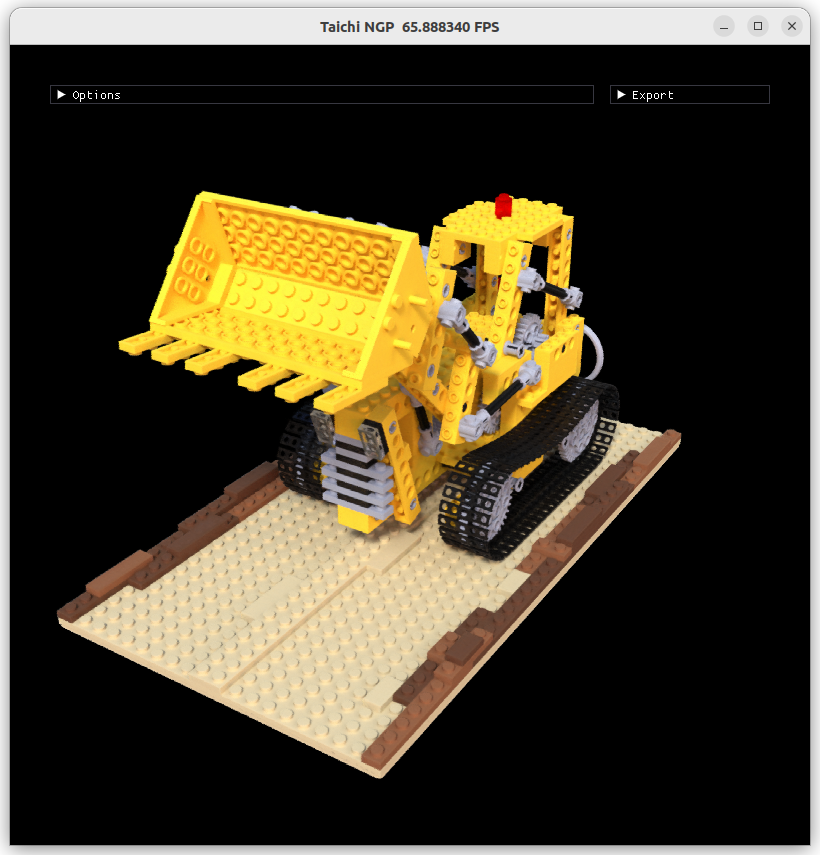
- 实现了 Instant NGP 的 forward 部分,并且可以实时渲染交互,只需要1GB的显存
- 通过 SharedArray 实现了简单的 Fully Fused MLP
- 目前提供了 8 个预训练的 Blender 渲染场景
目前因为 shared memory 在 CUDA 后端有 48KB 的限制,所以本项目的 Fully Fused MLP 并不完整,后续 Taichi 实现分配更大的 shared memory 后可以提速
仓库链接 https://github.com/Linyou/taichi-ngp-renderer
GUI 界面可以实现相机的交互、深度图可视化以及控制每条光线的采样数


预训练的渲染场景
具体使用方法请到 repo 中查看
9 个赞
zemora
#3
很精彩同样也是很辛苦的工作!有几个点:
- 在不加 --gui 参数的时候程序似乎会报错:
line 625, in render_frame
samples, N_alive, N_samples = self.render(max_samples=100, T_threshold=1e-4)
TypeError: NGP_fw.render() missing 2 required positional arguments: 'dist_to_focus' and 'len_dis'
-
f16 <= f32 这个 warning 有点多,可以处理一下。
-
shared memory 不支持 x64 架构,这个可否开头加一个检查,如果架构不符合则直接报错?
1 个赞
Shared memory确实不支持x64,回头我们加上!
LoYoT
#7
来更新一下:
- 之前写的 MLP 做了太多的同步,导致性能和 tiny-cuda-nn 差的有点多,新的代码目前渲染的速度已经超过原版的速度了,同等设置下 Taichi 有65 fps,对比使用 Pytorch 的 Binding (可以保证数据在GPU上) tiny-cuda-nn 只有45 fps
2. 目前可以在三个平台上正常运行了,Windos 和 Linux 可以使用 CUDA 和 Vulkan,MacOS 可以使用 Vulkan
5 个赞
zemora
#8
林同学,可以麻烦你去 taichi 的 repo 开个 PR 提交这个作品不?对 resource images 的处理可以参考这里:
2 个赞
zemora
#10
太赞了。我们 review 的同学还需要确认一下某些机器不能跑的原因,以及是不是需要就此明确给出提示。
1 个赞
一直准备自己复现这个forward的part,但苦于纯py的torch实现太慢,cuda太难写,刚调研到taichi发现已经有人做了类似的工作,我愿称之为大哥
CaiCai
#13
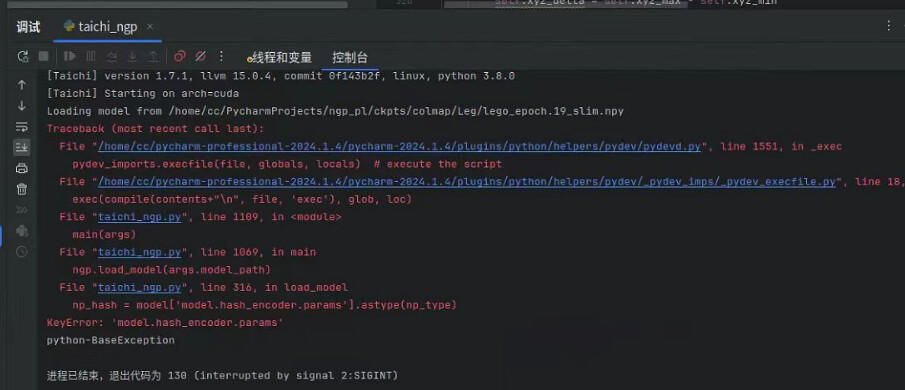
林同学您好!
请问为什么我将自己的场景用Ngp_pl训练完成,保存为npy文件后,运行Taichi-ngp时显示model.hash_encoder.params参数错误呢?