大家好,我是中科大物理学院大四学生,最近接触了taichi,用其写了一个折纸仿真的程序。
演示视频
基于Taichi太极平台实现的折纸仿真_哔哩哔哩_bilibili
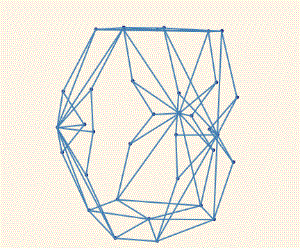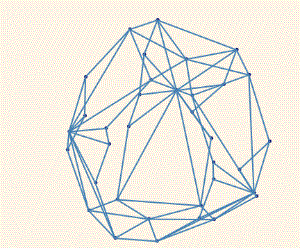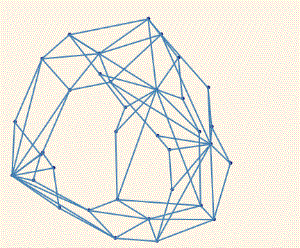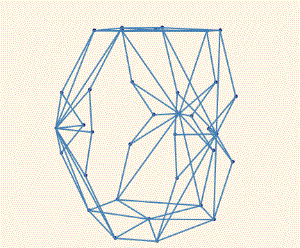 !
!
但我对并行计算,高性能计算相关知识还不是很了解,也只知道太极的一些基本用法。之后我打算对结构更复杂的模型进行仿真,担心我目前的电脑(i7-10875H,32G内存,RTX2060)跑不动。想问问是否有大佬愿意帮我看看代码,优化一下代码架构。
详细交流可加Q:1606938515
源码如下
import taichi as ti
import numpy as np
ti.init(arch=ti.gpu)
# ti.init(debug=True, arch=ti.cpu)
spring_Y = ti.field(dtype=ti.f32, shape=()) # Young's modulus
paused = ti.field(dtype=ti.i32, shape=())
drag_damping = ti.field(dtype=ti.f32, shape=())
dashpot_damping = ti.field(dtype=ti.f32, shape=())
max_num_particles = 35
num_beam = 78
num_cre = 48
num_foldcre = 24
num_alpha = 42
particle_mass = 0.001
dt = 1.666e-3
substeps = 10
pi = 3.14159265358
num_particles = ti.field(dtype=ti.i32, shape=())
# nodes pos and v_nodes
x = ti.Vector.field(3, dtype=ti.f32, shape=max_num_particles)
v = ti.Vector.field(3, dtype=ti.f32, shape=max_num_particles)
f = ti.Vector.field(3, dtype=ti.f32, shape=max_num_particles)
fixed = ti.field(dtype=ti.i32, shape=max_num_particles)
# beams
beam = ti.Vector.field(2, dtype=ti.i32, shape=num_beam)
beamlen = ti.field(dtype=ti.f32, shape=num_beam)
beamlen_tar = ti.field(dtype=ti.f32, shape=num_beam)
coef_axial = ti.Vector.field(3, dtype=ti.f32, shape=(num_beam, 2))
# crease
crease = ti.Vector.field(4, dtype=ti.i32, shape=num_cre)
creaseang = ti.field(dtype=ti.f32, shape=num_cre)
creaseang_tar = ti.field(dtype=ti.f32, shape=num_cre)
coef_crease = ti.Vector.field(3, dtype=ti.f32, shape=(num_cre, 4))
# angle
alpha = ti.Vector.field(3, dtype=ti.i32, shape=num_alpha)
alphaang = ti.field(dtype=ti.f32, shape=(num_alpha, 3))
alphaang_tar = ti.field(dtype=ti.f32, shape=(num_alpha, 3))
coef_alpha = ti.Vector.field(3, dtype=ti.f32, shape=(num_alpha, 3, 3))
# coeff
m = 1
EA = ti.field(dtype=ti.f32, shape=())
k_face = ti.field(dtype=ti.f32, shape=())
k_crease_face = ti.field(dtype=ti.f32, shape=())
k_crease_fold = ti.field(dtype=ti.f32, shape=())
ksi = ti.field(dtype=ti.f32, shape=())
force = ti.Vector.field(3, dtype=ti.f32, shape=1)
force_z = ti.field(dtype=ti.f32, shape=())
@ti.kernel
def substep():
n = num_particles[None]
# Compute force
for i in range(n):
# Gravity
f[i] = ti.Vector([0, 0, -2*particle_mass])
if i == 13:
f[i] += force[0]
# Compute axial force and damping
for i in range(num_beam):
c = 2 * ksi[None] * ti.sqrt(EA[None] / beamlen[i] * particle_mass)
for k in ti.static(range(2)):
f[beam[i][k]] += -EA[None] / beamlen[i] * (beamlen[i] - beamlen_tar[i]) * coef_axial[i, k]
# print(f[beam[i][k]])
f[beam[i][k]] += c * (v[beam[i][1 - k]] - v[beam[i][k]])
# Compute crease force
for i in range(num_foldcre):
l0 = (x[crease[i][1]]-x[crease[i][2]]).norm()
for k in ti.static(range(4)):
f[crease[i][k]] += -l0 * k_crease_fold[None] * (creaseang[i] - creaseang_tar[i]) * coef_crease[i, k]
for i in range(num_foldcre, num_cre):
l0 = (x[crease[i][1]]-x[crease[i][2]]).norm()
for k in ti.static(range(4)):
f[crease[i][k]] += -l0 * k_crease_face[None] * (creaseang[i] - creaseang_tar[i]) * coef_crease[i, k]
# Compute face force
for i in range(num_alpha):
for k in ti.static(range(3)):
for j in ti.static(range(3)):
f[alpha[i][j]] += -k_face[None] * (alphaang[i, k]-alphaang_tar[i, k]) * coef_alpha[i, k, j]
# We use a semi-implicit Euler (aka symplectic Euler) time integrator
for i in range(n):
if i > 6:
v[i] += dt * f[i] / particle_mass
v[i] *= ti.exp(-dt * drag_damping[None]) # Drag damping
x[i] += v[i] * dt
base_nodes = ti.Vector.field(3, float, 7)
top_nodes = ti.Vector.field(3, float, 7)
middle_nodes = ti.Vector.field(3, float, 3)
middle_nodes1 = ti.Vector.field(3, float, 12)
hard_nodes = ti.Vector.field(3, float, 6)
@ti.kernel
def generate_nodes_ori(D: ti.f32, L: ti.f32, H: ti.f32, theta: ti.f32):
# Taichi doesn't support using vectors as kernel arguments yet, so we pass scalars
num_particles[None] = 35
# base
base_nodes[6] = [0, 0, 0]
# for i in range(6):
# alpha = (i+1) * pi / 3
# base_nodes[i] = [D * ti.cos(alpha), D * ti.sin(alpha), 0]
lengt = ti.sqrt((D/2)**2+H**2)
beta = ti.atan2(D/2, H)
for i in range(3):
alpha = i * 2 * pi / 3 - beta - 7*pi/6
base_nodes[2*i] = [lengt*ti.cos(alpha), lengt*ti.sin(alpha), 0]
base_nodes[2*i+1] = [lengt*ti.cos(alpha+2*beta), lengt*ti.sin(alpha+2*beta), 0]
mi = base_nodes[5]
base_nodes[5] = base_nodes[4]
base_nodes[4] = base_nodes[3]
base_nodes[3] = base_nodes[2]
base_nodes[2] = base_nodes[1]
base_nodes[1] = base_nodes[0]
base_nodes[0] = mi
# top
for i in range(7):
# x[i+7] = x[i]
# x[i+7][2] += 2*L*ti.sin(theta)
top_nodes[i] = base_nodes[i]
top_nodes[i][2] += 2*L*ti.sin(theta)
# middle
for i in range(3):
alpha = (i+1) * 2 * pi / 3
middle_nodes[i] = [(H+L*ti.cos(theta))*ti.cos(alpha+pi/6),
(H+L*ti.cos(theta))*ti.sin(alpha+pi/6),
L*ti.sin(theta)]
# middle 1
for i in range(3):
alpha = (i+1) * 2 * pi / 3
middle_nodes1[2 * i][0] = (H + (L - D / 2) * ti.cos(theta)) * ti.cos(alpha + pi / 6) + D / 2 * ti.cos(alpha + pi * 2 / 3)
middle_nodes1[2 * i][1] = (H + (L - D / 2) * ti.cos(theta)) * ti.sin(alpha + pi / 6) + D / 2 * ti.sin(alpha + pi * 2 / 3)
middle_nodes1[2 * i][2] = (L - D / 2) * ti.sin(theta)
middle_nodes1[2 * i + 1][0] = (H + (L - D / 2) * ti.cos(theta)) * ti.cos(alpha + pi / 6) + D / 2 * ti.cos(alpha - pi / 3)
middle_nodes1[2 * i + 1][1] = (H + (L - D / 2) * ti.cos(theta)) * ti.sin(alpha + pi / 6) + D / 2 * ti.sin(alpha - pi / 3)
middle_nodes1[2 * i + 1][2] = (L - D / 2) * ti.sin(theta)
# middle 2
for i in range(6):
middle_nodes1[6 + i][0] = middle_nodes1[i][0]
middle_nodes1[6 + i][1] = middle_nodes1[i][1]
middle_nodes1[6 + i][2] = middle_nodes1[i][2]+D*ti.sin(theta)
# hard
leng2 = pow((middle_nodes1[0][0] - middle_nodes[0][0]), 2) + pow((middle_nodes1[0][1] - middle_nodes[0][1]), 2)
cosa = pow((D / 2 * ti.cos(theta)), 2) / leng2
for i in range(3):
alpha = (i+1) * 2 * pi / 3
mi00 = middle_nodes1[2 * i][0] + cosa * (-middle_nodes1[2 * i][0] + middle_nodes[i][0])
mi01 = middle_nodes1[2 * i][1] + cosa * (-middle_nodes1[2 * i][1] + middle_nodes[i][1])
mi10 = middle_nodes1[2 * i + 1][0] + cosa * (-middle_nodes1[2 * i + 1][0] + middle_nodes[i][0])
mi11 = middle_nodes1[2 * i + 1][1] + cosa * (-middle_nodes1[2 * i + 1][1] + middle_nodes[i][1])
hard_nodes[2 * i][0] = (H + L * ti.cos(theta)) * ti.cos(alpha + pi / 6) + D / 2 * ti.cos(alpha + pi * 2 / 3)
hard_nodes[2 * i][1] = (H + L * ti.cos(theta)) * ti.sin(alpha + pi / 6) + D / 2 * ti.sin(alpha + pi * 2 / 3)
hard_nodes[2 * i + 1][0] = (H + L * ti.cos(theta)) * ti.cos(alpha + pi / 6) + D / 2 * ti.cos(alpha - pi / 3)
hard_nodes[2 * i + 1][1] = (H + L * ti.cos(theta)) * ti.sin(alpha + pi / 6) + D / 2 * ti.sin(alpha - pi / 3)
hard_nodes[2 * i][0] = 2 * mi00 - hard_nodes[2 * i][0]
hard_nodes[2 * i][1] = 2 * mi01 - hard_nodes[2 * i][1]
hard_nodes[2 * i + 1][0] = 2 * mi10 - hard_nodes[2 * i + 1][0]
hard_nodes[2 * i + 1][1] = 2 * mi11 - hard_nodes[2 * i + 1][1]
hard_nodes[2 * i][2] = L * ti.sin(theta)
hard_nodes[2 * i + 1][2] = L * ti.sin(theta)
for i in range(6):
mid = middle_nodes1[2 * i]
middle_nodes1[2 * i] = middle_nodes1[2 * i + 1]
middle_nodes1[2 * i + 1] = mid
for i in range(3):
mid = hard_nodes[2 * i]
hard_nodes[2 * i] = hard_nodes[2 * i + 1]
hard_nodes[2 * i + 1] = mid
for i in range(5):
x[i] = base_nodes[i+1]
x[5] = base_nodes[0]
x[6] = base_nodes[6]
for i in range(6):
x[i+7] = middle_nodes1[i]
for i in range(3):
x[i+13] = middle_nodes[i]
for i in range(6):
x[i+16] = hard_nodes[i]
for i in range(6):
x[i+22] = middle_nodes1[i+6]
for i in range(5):
x[i+28] = top_nodes[i+1]
x[33] = top_nodes[0]
x[34] = top_nodes[6]
@ti.kernel
def generate_structures_ori():
# set beams
for i in range(6):
beam[i] = [i, 6]
beam[i + 6] = [i, (i+1) % 6]
beam[i + 12] = [i, i + 7]
beam[i + 18] = [i + 7, i // 2 + 13]
beam[i + 24] = [i + 7, i + 16]
beam[i + 30] = [i + 16, i // 2 + 13]
beam[i + 36] = [i + 16, i + 22]
beam[i + 42] = [i + 22, i // 2 + 13]
beam[i + 48] = [i + 22, i + 28]
beam[i + 54] = [i + 28, (i+1) % 6 + 28]
# faces
beam[i + 60] = [i, i // 2 + 13]
beam[i + 66] = [i + 28, i // 2 + 13]
beam[i + 72] = [i + 28, 34]
# set crease
for i in range(3):
# fold
# base
crease[i] = [6, 2 * i, 2 * i + 1, 13 + i]
# middle1
crease[2 * i + 3] = [2 * i, 2 * i + 7, 13 + i, 2 * i + 16]
crease[2 * i + 4] = [2 * i + 1, 13 + i, 2 * i + 8, 2 * i + 17]
# middle
crease[2 * i + 9] = [2 * i + 7, 2 * i + 16, 13 + i, 2 * i + 22]
crease[2 * i + 10] = [2 * i + 8, 13 + i, 2 * i + 17, 2 * i + 23]
# middle2
crease[2 * i + 15] = [2 * i + 16, 2 * i + 22, 13 + i, 2 * i + 28]
crease[2 * i + 16] = [2 * i + 17, 13 + i, 2 * i + 23, 2 * i + 29]
# top
crease[i + 21] = [13 + i, 2 * i + 28, 2 * i + 29, 34]
# face
crease[num_foldcre + 2 * i] = [2 * i, 2 * i + 1, 6, (2 * (i+1)) % 6]
crease[num_foldcre + 2 * i + 1] = [2 * i + 1, (2 * (i+1)) % 6, 6, (2 * (i+1)) % 6 + 1]
crease[num_foldcre + 2 * i + 6] = [2 * i + 1, 2 * i, 13 + i, 2 * i + 7]
crease[num_foldcre + 2 * i + 7] = [2 * i, 13 + i, 2 * i + 1, 2 * i + 8]
crease[num_foldcre + 2 * i + 12] = [2 * i + 22, 2 * i + 28, 13 + i, 2 * i + 29]
crease[num_foldcre + 2 * i + 13] = [2 * i + 23, 13 + i, 2 * i + 29, 2 * i + 28]
crease[num_foldcre + 2 * i + 18] = [2 * i + 28, 34, 2 * i + 29, (2 * (i+1)) % 6 + 28]
crease[num_foldcre + 2 * i + 19] = [2 * i + 29, 34, (2 * (i+1)) % 6 + 28, (2 * (i+1)) % 6 + 29]
# set alpha
for i in range(6):
alpha[i] = [i, (i+1) % 6, 6]
if i < 3:
alpha[i + 6] = [2 * i, 2 * i + 1, i + 13]
alpha[i + 33] = [2 * i + 28, 2 * i + 29, i + 13]
alpha[i + 9] = [i, i + 7, i // 2 + 13]
alpha[i + 15] = [i + 7, i + 16, i // 2 + 13]
alpha[i + 21] = [i + 16, i + 22, i // 2 + 13]
alpha[i + 27] = [i + 22, i + 28, i // 2 + 13]
alpha[i + 36] = [i + 28, (i+1) % 6 + 28, 34]
@ti.kernel
def calcu_beamlen():
for i in range(num_beam):
l12 = x[beam[i][1]]-x[beam[i][0]]
coef_axial[i, 0] = -l12.normalized()
coef_axial[i, 1] = l12.normalized()
beamlen[i] = l12.norm()
@ti.kernel
def calcu_creaseang():
# print('!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!')
for i in range(num_cre):
# calculate ang
vec12 = x[crease[i][1]] - x[crease[i][0]]
vec13 = x[crease[i][2]] - x[crease[i][0]]
vec43 = x[crease[i][2]] - x[crease[i][3]]
vec42 = x[crease[i][1]] - x[crease[i][3]]
vec23 = x[crease[i][2]] - x[crease[i][1]]
verti1 = (vec12.cross(vec13)).normalized()
verti2 = (vec43.cross(vec42)).normalized()
# if i == 47:
# force[0] = verti1 * force_z[None]
u = verti1.dot(verti2) / (verti1.norm() * verti2.norm())
u = min(u, 1)
creaseang[i] = ti.acos(u)
# print(i,creaseang[i])
a1 = (verti1.cross(verti2)).normalized()
a2 = vec23.normalized()
# print(a1, a2)
aa = a1 - a2
if aa.norm() < 0.0001:
creaseang[i] *= -1
# calculate plane ang
ang123 = ti.acos(-vec12.dot(vec23) / (vec12.norm() * vec23.norm()))
ang132 = ti.acos(vec13.dot(vec23) / (vec13.norm() * vec23.norm()))
ang423 = ti.acos(-vec42.dot(vec23) / (vec42.norm() * vec23.norm()))
ang432 = ti.acos(vec43.dot(vec23) / (vec43.norm() * vec23.norm()))
# calculate h
h1 = vec13.norm() * ti.sin(ang132)
h4 = vec43.norm() * ti.sin(ang432)
# calculate coefficient
coef_crease[i, 0] = verti1 / h1
coef_crease[i, 3] = verti2 / h4
coef_crease[i, 2] = - verti1 / h1 / ti.tan(ang123) / (1 / ti.tan(ang123) + 1 / ti.tan(ang132)) \
- verti2 / h4 / ti.tan(ang423) / (1 / ti.tan(ang432) + 1 / ti.tan(ang423))
coef_crease[i, 1] = - verti1 / h1 / ti.tan(ang132) / (1 / ti.tan(ang123) + 1 / ti.tan(ang132)) \
- verti2 / h4 / ti.tan(ang432) / (1 / ti.tan(ang432) + 1 / ti.tan(ang423))
@ti.kernel
def calcu_alphaang():
# print('ssssssssssssssss')
for i in range(num_alpha):
vec12 = x[alpha[i][1]] - x[alpha[i][0]]
vec31 = x[alpha[i][0]] - x[alpha[i][2]]
vec23 = x[alpha[i][2]] - x[alpha[i][1]]
vnorm = (vec12.cross(-vec31)).normalized()
# angle
alphaang[i, 0] = ti.acos(vec12.dot(-vec31) / (vec12.norm() * vec31.norm()))
alphaang[i, 1] = ti.acos(vec23.dot(-vec12) / (vec12.norm() * vec23.norm()))
alphaang[i, 2] = ti.acos(-vec23.dot(vec31) / (vec23.norm() * vec31.norm()))
for j in ti.static(range(3)):
coef_alpha[i, j, (j - 1) % 3] = vnorm.cross(x[alpha[i][(j - 1) % 3]] - x[alpha[i][j]]) / (
x[alpha[i][(j - 1) % 3]] - x[alpha[i][j]]).norm_sqr()
coef_alpha[i, j, (j + 1) % 3] = - vnorm.cross(x[alpha[i][(j + 1) % 3]] - x[alpha[i][j]]) / (
x[alpha[i][(j + 1) % 3]] - x[alpha[i][j]]).norm_sqr()
coef_alpha[i, j, j] = - coef_alpha[i, j, (j - 1) % 3] - coef_alpha[i, j, (j + 1) % 3]
def T(a):
phi, theta = np.radians(-48), np.radians(20)
a = a
x, y, z = a[:, 0], a[:, 1], a[:, 2]
c, s = np.cos(phi), np.sin(phi)
C, S = np.cos(theta), np.sin(theta)
x, y = x * c + y * s, y * c - x * s
u, v = x + 0.5, z * C + y * S + 0.2
return np.array([u, v]).swapaxes(0, 1)
def main():
gui = ti.GUI('Origami by Vec', background_color=0xFDF5E6)
EA[None] = 1
k_face[None] = 0.01
k_crease_face[None] = 1
k_crease_fold[None] = 0.0208
# k_crease_fold[None] = 0.007125
ksi[None] = 0.00
force_z[None] = 0.00
drag_damping[None] = 100
generate_structures_ori()
generate_nodes_ori(0.03, 0.04, 0.01*ti.sqrt(3), pi / 3*1.128)
# generate_nodes_ori(0.03, 0.04, 0.01 * ti.sqrt(3), pi / 2)
calcu_alphaang()
calcu_beamlen()
calcu_creaseang()
x[34]=[6,6,6]
for i in range(num_beam):
beamlen_tar[i] = beamlen[i]
for i in range(num_cre):
creaseang_tar[i] = creaseang[i]
# creaseang_tar[i] = 0
for i in range(num_alpha):
for j in range(3):
alphaang_tar[i, j] = alphaang[i, j]
generate_nodes_ori(0.03, 0.04, 0.01*ti.sqrt(3), pi / 3 * 1.128)
link = beam.to_numpy()
# crease_fold = crease.to_numpy()
# triangle = alpha.to_numpy()
cnt = 0
fz = 0
while True:
cnt += 1
# force[0] = [0.1*ti.sin(cnt/60), 0.1*ti.cos(cnt/60), -0.05]
force[0] = [0, 0, 0.1*ti.sin(cnt/60)]
# force[0] = [0, 0, -force_z[None]]
# fz += 0.005
# force_z[None] = min(0.3, fz)
# crease_fold_start = pos[crease_fold[24:, 1], :]
# crease_fold_end = pos[crease_fold[24:, 2], :]
# triangle_1 = pos[triangle[:, 0], :]
# triangle_2 = pos[triangle[:, 1], :]
# triangle_3 = pos[triangle[:, 2], :]
for e in gui.get_events(ti.GUI.PRESS):
if e.key in [ti.GUI.ESCAPE, ti.GUI.EXIT]:
exit()
elif e.key == gui.SPACE:
paused[None] = not paused[None]
elif e.key == 'y':
force_z[None] -= 0.005
elif e.key == 'u':
force_z[None] += 0.005
if not paused[None]:
for step in range(substeps):
calcu_beamlen()
calcu_creaseang()
calcu_alphaang()
substep()
pos = 8 * x.to_numpy()
link_pos_start = pos[link[:, 0], :]
link_pos_end = pos[link[:, 1], :]
gui.circles(T(pos), radius=3, color=0x191970)
gui.lines(T(link_pos_start), T(link_pos_end), color=0x4682B4, radius=1.5)
# gui.lines(T(crease_fold_start), T(crease_fold_end), color=0xFF0000, radius=1)
# gui.triangles(T(triangle_1), T(triangle_2), T(triangle_3), color=0xFF0000)
# gui.text(
# content=
# f'Left click: add mass point (with shift to fix); Right click: attract',
# pos=(0, 0.99),
# color=0x0)
# gui.text(content=f'C: clear all; Space: pause',
# pos=(0, 0.95),
# color=0x0)
gui.text(content=f'Load [N]: {force_z[None]:.3f}',
pos=(0, 0.99),
color=0x0)
gui.text(content=f'Top Position [mm]: {1000 * x[34][2]:.2f}',
pos=(0, 0.95),
color=0x0)
gui.text(content=f'Extension [mm]: {1000 * (0.074 - x[34][2]):.2f}',
pos=(0, 0.91),
color=0x0)
# gui.text(content=f'D: Drag damping {drag_damping[None]:.2f}',
# pos=(0, 0.85),
# color=0x0)g {dash
# # gui.text(content=f'X: Dashpot dampinpot_damping[None]:.2f}',
# pos=(0, 0.8),
# color=0x0)
gui.show()
# if cnt % 500 == 0:
# print(force_z[None], 1000 * (0.074 - x[34][2]))
# force_z[None] = min(0.25, fz)
if __name__ == '__main__':
main()
