Dear Taichi community,
I am working on a pet project to generate an optimal tracing path, given a certain stencil, to produce a desired design by dragging the stencil along the tracing path. It is a form of slicer approach to polymerize resins with a laser (for example).
The goal is summarized in the figure below.
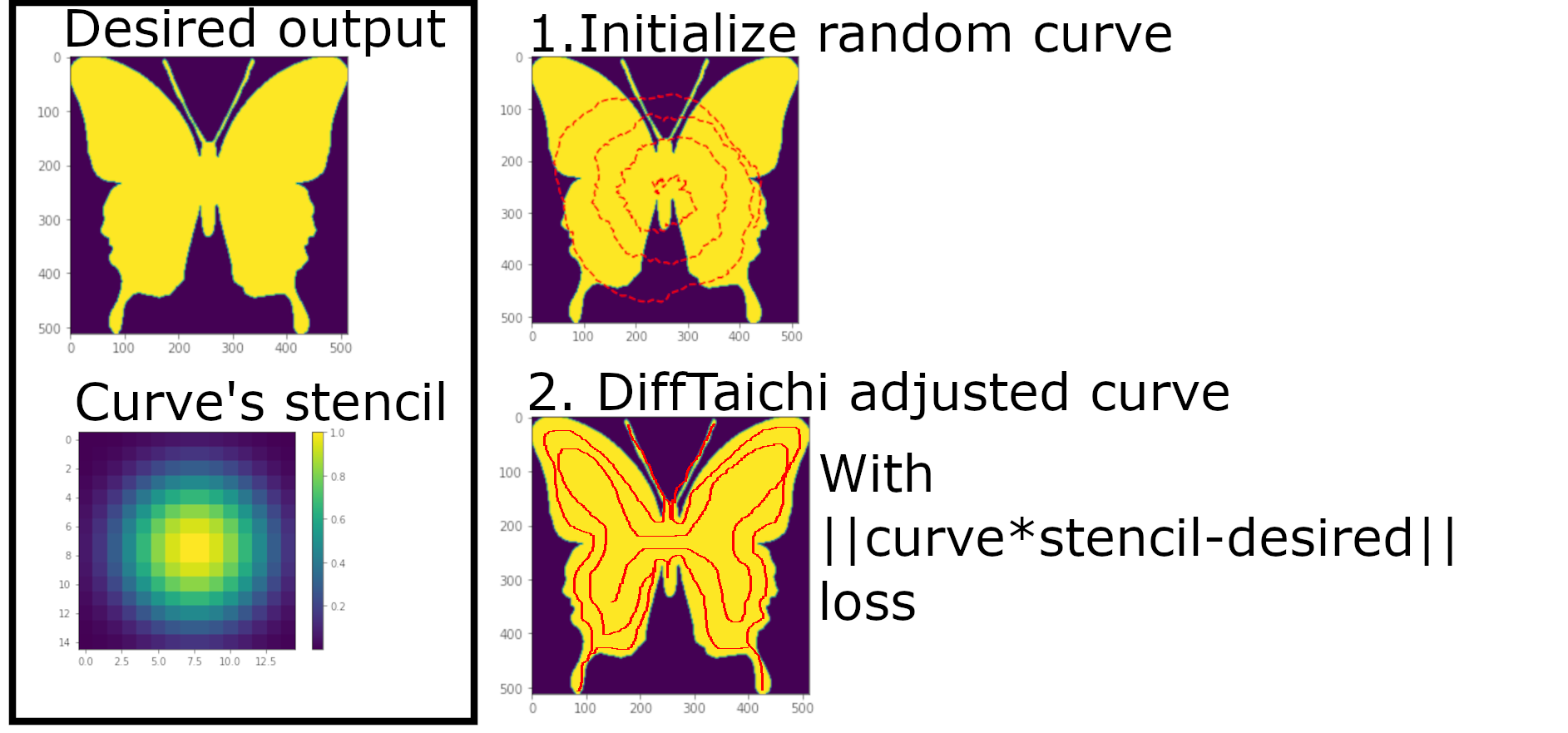
Fig1. illustrates the concept. We would like to draw a butterfly by dragging the stencil (essentially a wide gaussian dot) over some curve, and convolve the stencil with the curve. On the right side, the butterfly is illustrated as the goal. Initially, a random curve is generated, which does not reproduce the butterfly well. The hope is to use difftaichi to adjust the curve into a shape that produces the butterfly (by L2 loss).
My curve object, xy_ps, is a 4xN field where the first two rows are the x,y coordinates of the curve. The third and fourth rows stand for power and speed (both of which modulate how much of the stencil will be printed at a given coordinate). In principle, the optimization would adjust the location of the coordinates, the intensity and tracing speed at each coordinate.
In brief, the algorithm I wrote works, but does not have gradients for the first two rows of xy_ps : only the power and speed are adjusted over iterations, the coordinates remain still. I have a canvas in which I draw (512,512 field). My kernel takes the x,y coordinates of the curve (floats), casts them to int32 and loops over the size of the stencil to deposit the pixel values into my canvas. I’m suspecting the casting is the issue, but I do not understand how to debug this, or work around it.
Below is the code.
import numpy as np
image_size=512
#make mathematicaly butterfly because I can only upload 1 image to the post
xx,yy=np.meshgrid(np.arange(image_size),np.arange(image_size))
r=(xx-image_size//2)**2+(yy-image_size//2)**2
t=np.arctan2(yy-image_size//2,xx-image_size//2)
e,s,c=np.exp,np.sin,np.cos
target_img=((e(s(t))-2*c(4*t)+s((2*t-np.pi)/24.)**5)>r/20000).astype(int)
n_steps=100 #how many times we try to update the curve
n_pts=5000 #number of points in the curve (start small for now)
laser_size=15
#create a stencil
xx,yy=np.meshgrid((np.arange(laser_size)-laser_size/2.),np.arange(laser_size)-laser_size/2.) #center the grid as "(0,0)" in middle of image
from scipy.special import airy #bessel function
laser_spot_as_power=airy((np.sqrt( xx**2+yy**2)/5 )**2)[0]
laser_spot=laser_spot_as_power/np.max(laser_spot_as_power)
##Start of Taichi code here###
import taichi as ti
ti.reset()
ti.init(arch=ti.gpu)
#define the canvas in which to paint, the metacurve to modify over time, the laser spot (pencil stroke), and the target
#image we wish to recreate.
canv = ti.field(dtype=ti.f32, shape=[image_size, image_size], needs_grad=True)
xy_ps = ti.field(dtype=ti.f32, shape=[4,n_pts], needs_grad=True)
stencil = ti.field(dtype=ti.f32, shape=[laser_size,laser_size])
target = ti.field(dtype=ti.f32, shape=[image_size,image_size])
#allocate a loss - used to track how close we will match the target image with our metacurve painter.
loss = ti.field(float, (), needs_grad=True) #loss function to minimize
stencil.from_numpy(laser_spot_as_power)
target.from_numpy(target_img)
#initialize random metacurve
init_pwr,init_speed=np.ones(n_pts),np.ones(n_pts)
r=np.cumsum( np.random.randint(-5,5,size=n_pts) )
theta=np.cumsum( np.random.rand(n_pts))*5/180.*np.pi
x=r*np.cos(theta)
y=r*np.sin(theta)
x=x/(np.max(x)-np.min(x))*400
y=y/(np.max(y)-np.min(y))*400
x=x-np.mean(x)+image_size/2
y=y-np.mean(y)+image_size/2
xy_ps.from_numpy(np.vstack((x,y,init_pwr,init_speed)))
#learning rate : how fast to nudge the curve around
lr=1e-2
@ti.kernel
def init_canvas():
for p in ti.grouped(canv):
canv[p] = 0.0
@ti.kernel
def run_polymerize_cleartext():
for i in range(1,n_pts):
x=xy_ps[0,i]
y=xy_ps[1,i]
powr=xy_ps[2,i]
speed=xy_ps[3,i]
x_pre=xy_ps[0,i-1] #the first distance will be 0, so no writing, but it's okay.
y_pre=xy_ps[1,i-1]
dist2= ti.pow(x-x_pre,2)+ti.pow(y-y_pre,2) #consecutive distance between curve coordinates
time_dwell=ti.sqrt(dist2)/speed #time spent writing the stencil
for k,l in ti.ndrange(laser_size,laser_size): #deposit the stencil into the canvas
xo=ti.cast( x-laser_size//2+k,ti.i32) #is cast causing the issue for gradients?
yo=ti.cast(y-laser_size//2+l,ti.i32)
canv[xo,yo]+=laser_spot[k,l]*time_dwell*powr
@ti.kernel
def run_polymerize_short_code():
for i in range(1,n_pts):
dist2= ti.pow(xy_ps[0,i]-xy_ps[0,i-1],2)+ti.pow(xy_ps[1,i]-xy_ps[1,i-1],2)
for k,l in ti.ndrange(laser_size,laser_size):
canv[xy_ps[0,i]-laser_size//2+k,xy_ps[1,i]-laser_size//2+l]+=stencil[k,l]*xy_ps[2,i]*ti.sqrt(dist2)/xy_ps[3,i]
@ti.kernel
def compute_loss():
for i,j in canv:
ti.atomic_add(loss,ti.abs(canv[i,j]-target[i,j]))
@ti.kernel
def update_xy_ps():
for i,j in xy_ps.grad:
xy_ps[i,j]-=lr*xy_ps.grad[i,j] #go in the opposite direction of loss gradient
gui = ti.GUI('evol',image_size)
while gui.running and not gui.get_event(gui.ESCAPE):
for step in range(n_steps):
init_canvas()
with ti.Tape(loss):
#run_polymerize_cleartext() #has no gradients at all
run_polymerize_short_code() #has gradients only for power and speed
compute_loss()
update_xy_ps()
print('Loss= ', loss[None])
gui.set_image(canv.to_numpy())
gui.show()
- By calling xy_ps.grad.to_numpy(), I can see that the first two rows are zero.
- I provide a cleartext version of the kernel (run_polymerize_cleartext), but I think I am breaking some kernel simplicity rules, and there’s no gradients at all with that kernel
- I shortened the kernel to its bare bones in the kernel with the same name that ends with …short_code
- I don’t fully understand why the canvas (canv variable) requires needs_grad=True for the gradients to flow. Is that because the loss requires the canvas, so the canvas has to have gradients turned on?
- Is there a clear reason why the x,y coordinates do not get pushed around (i.e have no gradients?)
Thanks for your help