import numpy as np
import taichi as ti
import time
ti.init(arch=ti.gpu)
@ti.kernel
def sum_thousand(x: ti.types.ndarray()) -> ti.f32:
s = 0.0
for i in range(1000):
s += x[i]
return s
xs1 = np.arange(0, 10, 0.001)
start = time.time()
for i in range(1000):
sum_thousand(xs1)
print("duration(s): ", time.time() - start)
xs2 = np.arange(0, 100, 0.001)
start = time.time()
for i in range(1000):
sum_thousand(xs2)
print("duration(s): ", time.time() - start)
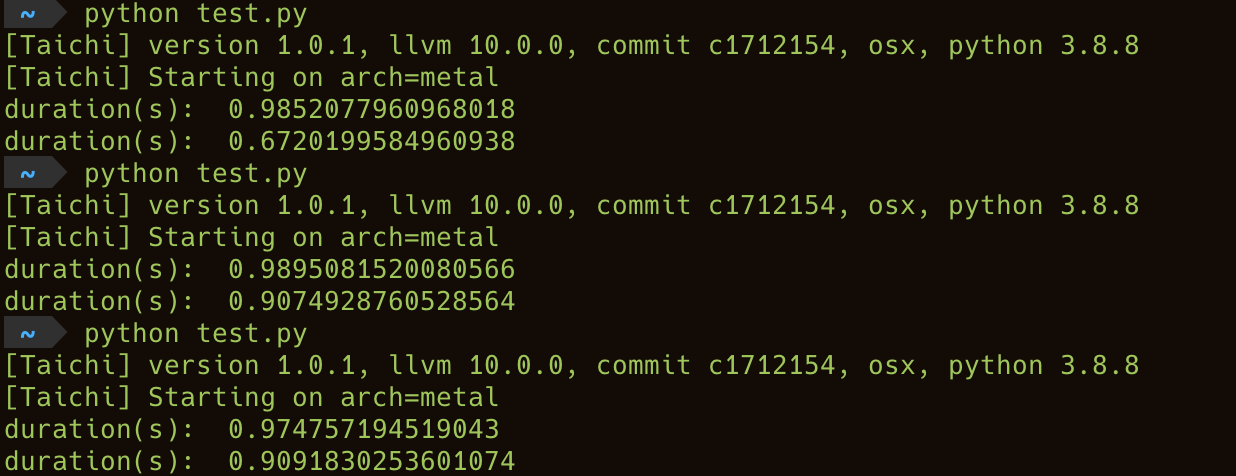
执行输出为:
[Taichi] Starting on arch=cuda
duration(s): 0.659170389175415
duration(s): 1.0771942138671875
import numpy as np
import taichi as ti
import time
ti.init(arch=ti.gpu, default_fp=ti.f32)
@ti.kernel
def sum_thousand(x: ti.types.ndarray()) -> ti.f32:
s = 0.0
for i in range(1000):
s += x[i]
return s
xs1 = np.arange(0, 10, 0.001,dtype=np.float32)
sum_thousand(xs1)
start = time.time()
for i in range(1000):
sum_thousand(xs1)
print("duration(s): ", time.time() - start)
xs2 = np.arange(0, 100, 0.001,dtype=np.float32)
sum_thousand(xs2)
start = time.time()
for i in range(1000):
sum_thousand(xs2)
print("duration(s): ", time.time() - start)
import numpy as np
import taichi as ti
import time
ti.init(arch=ti.gpu, default_fp=ti.f32)
@ti.kernel
def sum1000(x: ti.types.ndarray()) -> ti.f32:
s = 0.0
for i in range(1000):
s += x[i]
return s
def test(x):
sum1000(x)
start = time.time()
for i in range(1000):
sum1000(x)
print("duration(s): ", time.time() - start)
test(np.arange(0, 10, 0.001, dtype=np.float32))
test(np.arange(0, 100, 0.001, dtype=np.float32))
test(np.arange(0, 100, 0.001))
输出为
[Taichi] Starting on arch=cuda
duration(s): 0.8674345016479492
duration(s): 0.9991717338562012
duration(s): 1.772221565246582