A while ago I implemented MLS-MPM… With a flaw. The weights my quadratic kernel would spit out were sometimes exceeding 1. I just did a lazy fix and scaled it all down. Today a little video got me to read through the taichi implementation of mls-mpm. I noticed how theres some trick used to compute weights.
What exactly is that trick? Where does it originate from? I’m not very knowledgeable in this field so it might be something obvious, and in that case I’m sorry
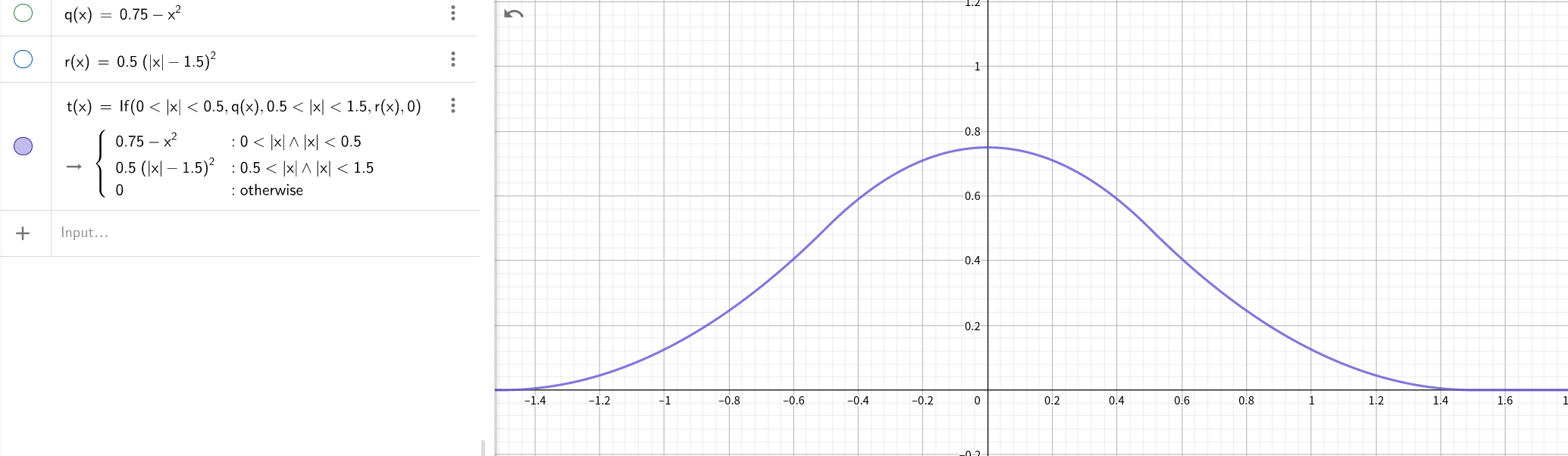
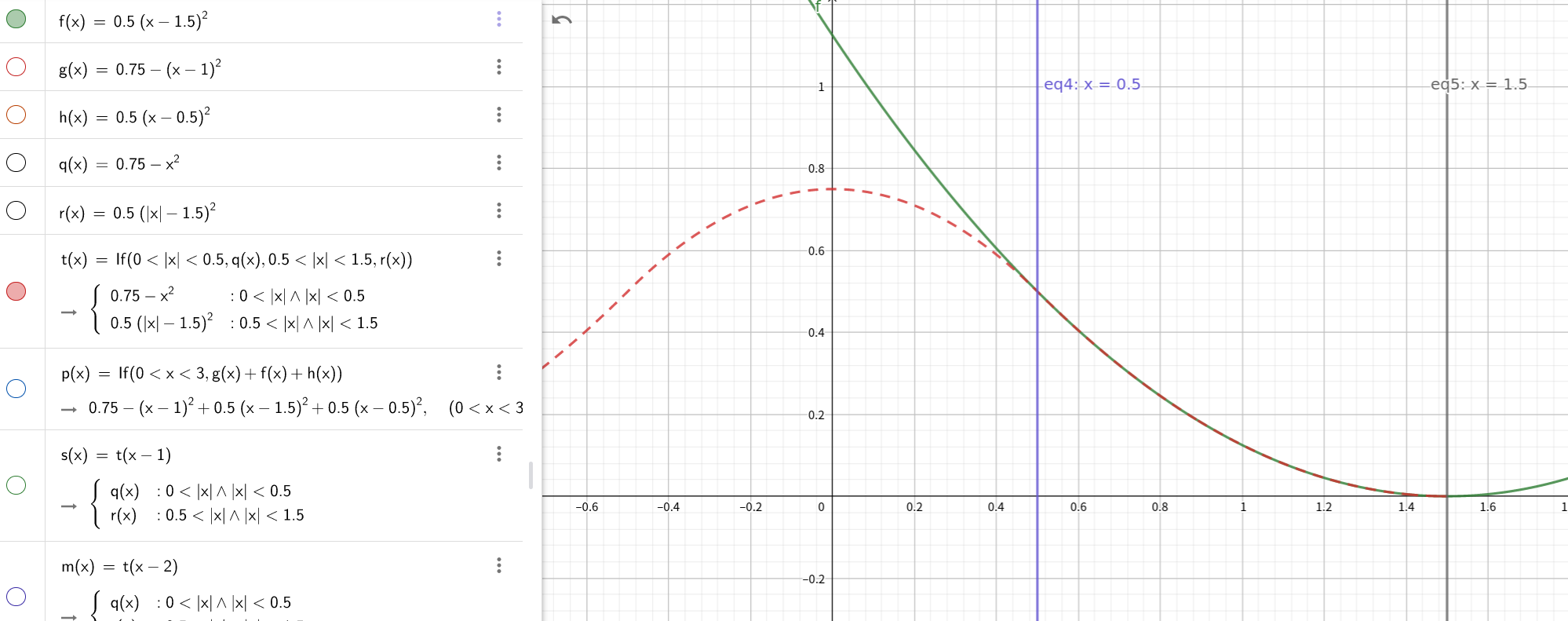
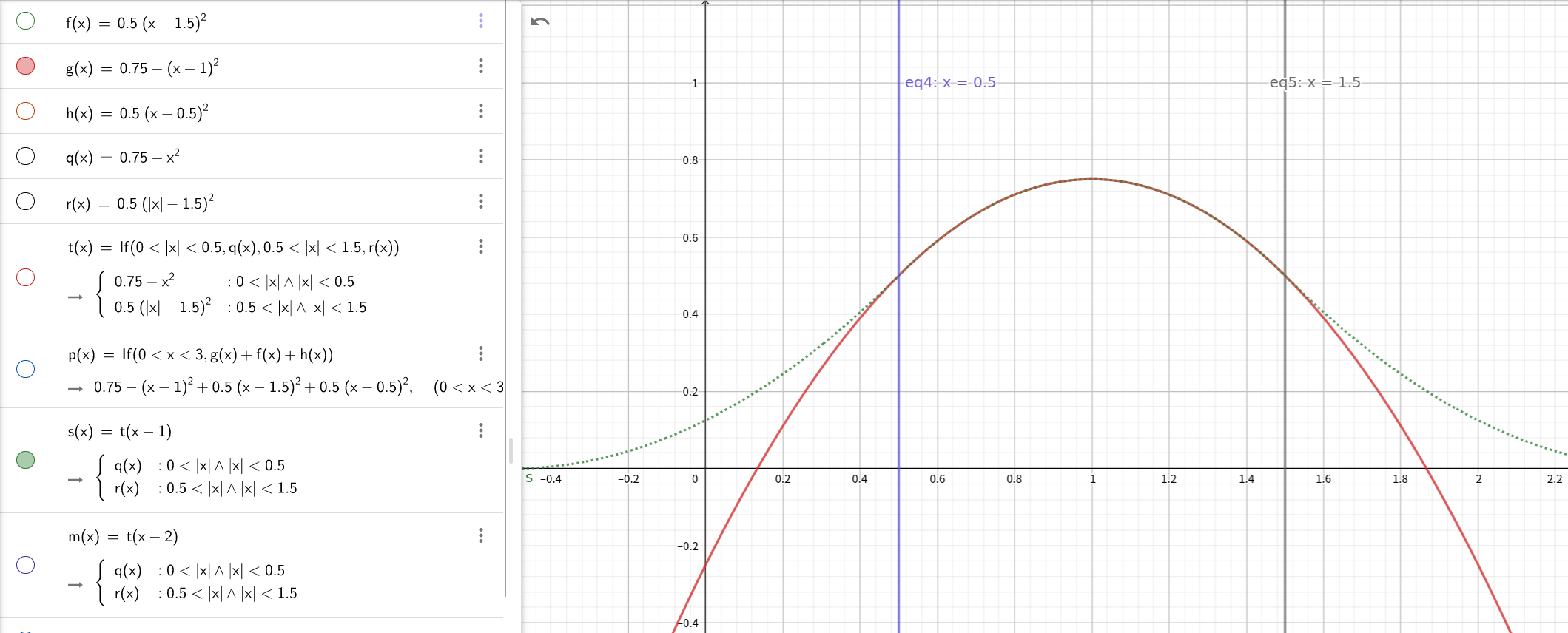
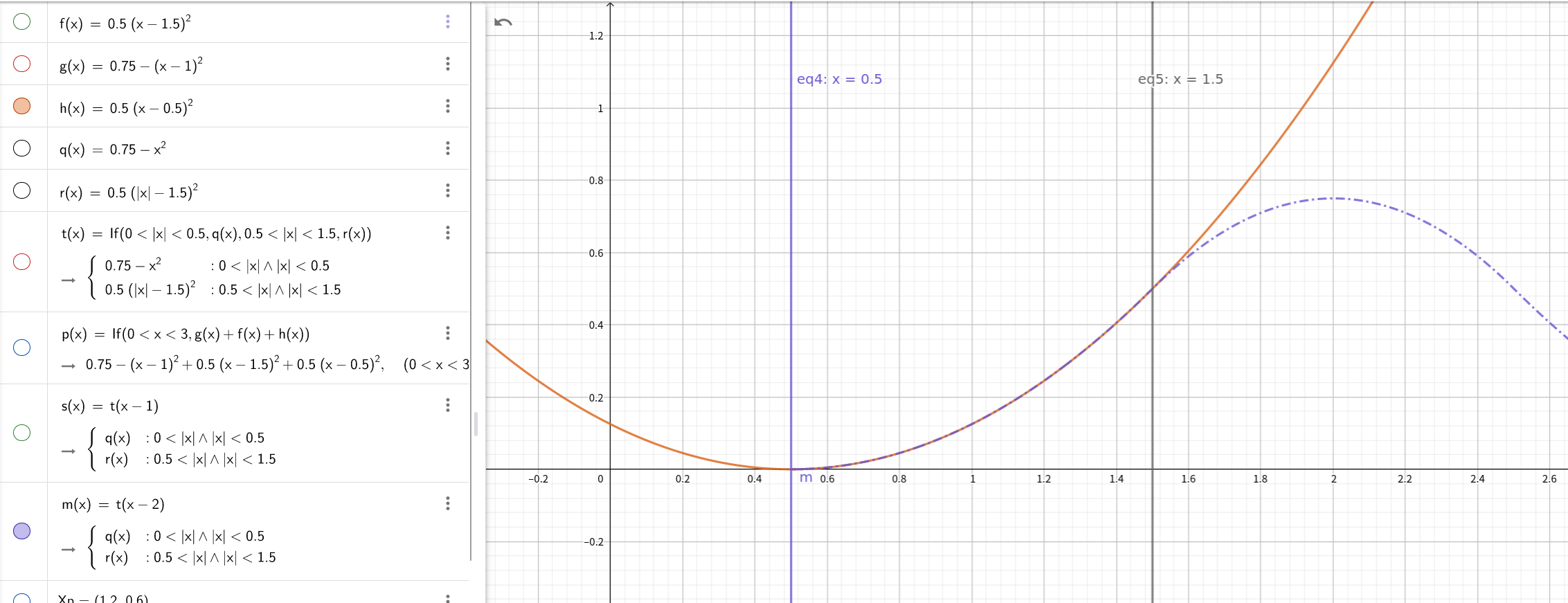
The three-components of w correspond to the three parts of N(x).
Specifically, w[0] = 0.5 * (1.5 - fx)**2 corrsponds to f(x). w[1] = 0.75 - (fx - 1)**2 corrsponds to g(x). w[2] = 0.5 * (fx - 0.5)**2 corrsponds to h(x).
Because the kernel function can exceed one! From my own experience, some kernel does not obey the rule of normalization ( integrating from -inf to inf equals one). But they work as well!
In fact, I think the kernel is just a scaling function that convert the distance of nearby particles into a coeffient, which will fade out after the particles are too far away between each other.