hhh, 网上找的啦 ![]()
这个视频也太炫酷了吧 ![]() ,果然大佬是没有知识盲区的。现在程序里的曲面边界算法太糙了,还容易被各种反射波干扰,画出的vorticity没有这么干净漂亮,后续再找个好点的算法算算看
,果然大佬是没有知识盲区的。现在程序里的曲面边界算法太糙了,还容易被各种反射波干扰,画出的vorticity没有这么干净漂亮,后续再找个好点的算法算算看 ![]()
1 个赞
哈哈,巧了巧了,不过我不是专门搞LBM的,只是发现这个算法原理很amazing,和NS方程长得差十万八千里居然也能算流体。
Fortran我现在还在用 ![]() ,没办法祖传代码都不愿意改它。写taichi几乎真的是和python无缝链接,体验不要太爽,不过要写得效率高还是要多练习练习。
,没办法祖传代码都不愿意改它。写taichi几乎真的是和python无缝链接,体验不要太爽,不过要写得效率高还是要多练习练习。
1 个赞
学到了 ![]()
边界看上去确实是有点问题。

solve()
import matplotlib
def solve(self):
gui = ti.GUI('lbm solver', (self.nx, self.ny*2))
self.init()
for i in range(self.steps):
self.collide_and_stream()
self.update_macro_var()
self.apply_bc()
self.get_display_var()
## vor
vel = self.vel.to_numpy()
ugrad = np.gradient(vel[:, :, 0])
vgrad = np.gradient(vel[:, :, 1])
du_dy = ugrad[1]
dv_dx = vgrad[0]
## vor = dv/dx - du/dy
vor = dv_dx - du_dy
## 颜色映射
colors = [
(1, 1, 0),
(0.953, 0.490, 0.016),
(0, 0, 0),
(0.176, 0.976, 0.529),
(0, 1, 1)
]
my_cmap = matplotlib.colors.LinearSegmentedColormap.from_list(
'my_cmap', colors)
vor_img = cm.ScalarMappable(cmap=my_cmap).to_rgba(vor)
vel_img = cm.plasma(self.display_var.to_numpy() / 0.15)
# numpy 的 y 方向貌似和 taichi 相反
img = np.concatenate((vor_img, vel_img), axis=1)
gui.set_image(img)
# gui.show()
gui.show(f'frame/{i:04d}.png')
if (i % 1000 == 0):
print('Step: {:}'.format(i))
4 个赞
牛皮牛皮,这个涡量着色我怎么调colormap都没搞出这个效果。目前圆柱的边界是用阶梯锯齿来替代的,特别糙。上下边界用的无滑移壁面条件,所以也剪切产生了涡,这个可以调整。
1 个赞
我把 matplotlib 的 colormap 反复的看了几遍,中间是黑色的就没几个,一般还都是整体是暗色的。
没办法只能自己调了。
这一顿操作,然后我这边帧率就只有十几帧了,只画一个图时 30fps+ 稳稳地。
@yuanming
taichi 如果能收集一些常用的 @ti.func 就好了。社区驱动就行。
定好标准,大家提交。
像 Shader 的辅助函数:mix、clamp、smoothstep、fract、…
2 个赞
@woclass 好主意!我们内部其实讨论过要不要把glsl之类的shader语言的常用函数加进taichi。后来主要是担心API变得特别庞杂难以维护, 所以就暂时只加入了最核心的函数,毕竟API易增难减。
我觉得可以开一个taichi_shaders Python包来定义这些shader常用函数。这样用户可以直接
import taichi_shaders as ts
@ti.kernel
def shade():
ts.mix(...)
7 个赞
I’d love this, will we add it in taichi.glsl or taichi_glsl (in another package)?
2 个赞
@yuanming Added https://github.com/taichi-dev/taichi_glsl, would you mind share me some skills about making an PyPI package? Btw, we should try to release v0.6.8 today/tonight to match next GAMES 201 lecture.
3 个赞
@yuanming @woclass taichi_glsl uploaded, run pip install -i https://test.pypi.org/simple/ taichi_glsl and enjoy youself with GLSL-alike functions!
from taichi_glsl import *
image = vec_array(3, float, 512, 512)
@ti.kernel
def paint():
for i, j in image:
# TODO: add `for coor in view(image):` instead
coor = view(image, i, j)
image[i, j] = smoothstep(distance(coor, vec(0.5, 0.5)), 0.5, 0.44) * vec(coor.x, coor.y, 0.0)
paint()
ti.imshow(image)
4 个赞
边界的ringing用MRT(multi-relaxation time)可以改善一些,以前写过一个http://www.cfluid.com/forum.php?mod=viewthread&tid=126105
1 个赞
哇,LBM大佬现身,谢谢指导!请教一下,你说的ringing是指入口那些波动么,我试过把计算区域设大,然后边界都设置成出流边界,可以消除这一现象。另外,MRT比单松弛因子的消耗大概多多少?
入口的波动是因为初始分布没有到平衡态,可以用和边界条件匹配的宏观量先算一个近似的平衡分布。ringing是指边界附近因为数值原因造成的固定的高频信号。MRT主要是碰撞的时候多了两次矩阵乘法,是(部分)构造出来的整形正交矩阵,很多1和0,全部inline还是挺快的,直接用CUDA写应该是比taichi快一些。。。
也有可能是nu太小了,加湍流模型可以稳定住。
圆柱左边的就是ringing,换成halfway bounce back就明显了。出入流边界不清楚有没有问题,但是Re应该是2000吧,同Re减小入流速度似乎要稳定一些。
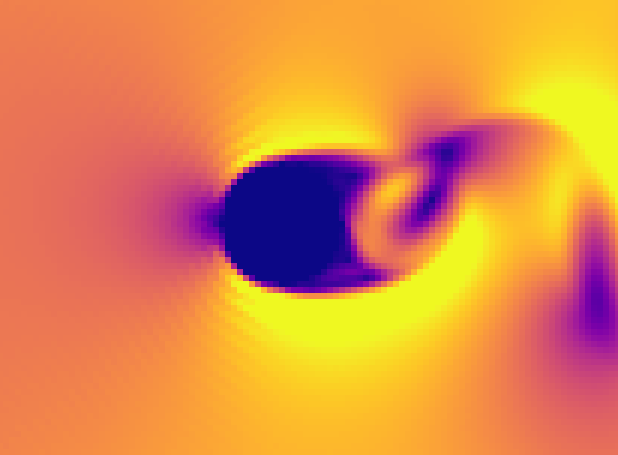
4 个赞
新手都傻了,也就是说这是一个用计算机图形学框架写的,满足CFD精度要求的LBM求解器? ![]()
最近在研究CFD 看来得学一学这个TaiChi框架了。
2 个赞
taichi 是编程语言哦,只是偏向于图形学的应用。
你用他来写什么是没有限制的。
1 个赞
好的,涨知识了,谢谢大佬!
改了个MRT的,Re到了50000,可以模拟湍流了。入口波动的问题还不清楚。
貌似opengl后端比cuda快了近一倍。
import taichi as ti
import numpy as np
import matplotlib.cm as cm
import matplotlib.pyplot as plt
ti.init(arch=ti.gpu)
@ti.data_oriented
class lbm_solver:
def __init__(self,
nx, # domain size
ny,
niu, # viscosity of fluid
# [left,top,right,bottom] boundary conditions: 0 -> Dirichlet ; 1 -> Neumann
bc_type,
bc_value, # if bc_type = 0, we need to specify the velocity in bc_value
cy=0, # whether to place a cylindrical obstacle
# location and radius of the cylinder
cy_para=[0.0, 0.0, 0.0],
steps=600000): # total steps to run
self.nx = nx # by convention, dx = dy = dt = 1.0 (lattice units)
self.ny = ny
self.niu = niu
self.tau = 3.0 * niu + 0.5
self.inv_tau = 1.0 / self.tau
self.rho = ti.var(dt=ti.f32, shape=(nx, ny))
self.vel = ti.Vector(2, dt=ti.f32, shape=(nx, ny))
self.mask = ti.var(dt=ti.f32, shape=(nx, ny))
self.display_var = ti.var(dt=ti.f32, shape=(nx, ny))
self.f_old = ti.Vector(9, dt=ti.f32, shape=(nx, ny))
self.f_new = ti.Vector(9, dt=ti.f32, shape=(nx, ny))
self.w = ti.var(dt=ti.f32, shape=9)
self.e = ti.var(dt=ti.i32, shape=(9, 2))
self.bc_type = ti.var(dt=ti.i32, shape=4)
self.bc_value = ti.var(dt=ti.f32, shape=(4, 2))
self.cy = cy
self.cy_para = ti.var(dt=ti.f32, shape=3)
self.bc_type.from_numpy(np.array(bc_type, dtype=np.int32))
self.bc_value.from_numpy(np.array(bc_value, dtype=np.float32))
self.cy_para.from_numpy(np.array(cy_para, dtype=np.float32))
self.steps = steps
arr = np.array([4.0 / 9.0, 1.0 / 9.0, 1.0 / 9.0, 1.0 / 9.0, 1.0 / 9.0, 1.0 / 36.0,
1.0 / 36.0, 1.0 / 36.0, 1.0 / 36.0], dtype=np.float32)
self.w.from_numpy(arr)
arr = np.array([[0, 0], [1, 0], [0, 1], [-1, 0], [0, -1], [1, 1],
[-1, 1], [-1, -1], [1, -1]], dtype=np.int32)
self.e.from_numpy(arr)
@ti.func # compute equilibrium distribution function
def f_eq(self, i, j, k):
eu = ti.cast(self.e[k, 0], ti.f32) * self.vel[i, j][0] + ti.cast(self.e[k, 1],
ti.f32) * self.vel[i, j][1]
uv = self.vel[i, j][0]**2.0 + self.vel[i, j][1]**2.0
return self.w[k] * self.rho[i, j] * (1.0 + 3.0 * eu + 4.5 * eu**2 - 1.5 * uv)
@ti.kernel
def init(self):
for i, j in self.rho:
self.vel[i, j][0] = 0.0
self.vel[i, j][1] = 0.0
self.rho[i, j] = 1.0
self.mask[i, j] = 0.0
for k in ti.static(range(9)):
self.f_new[i, j][k] = self.f_eq(i, j, k)
self.f_old[i, j][k] = self.f_new[i, j][k]
# half way bounce back for no-slip boundary
# borders
if (i == self.nx or j == 0 or j == self.ny):
self.mask[i, j] = 1.0
# cylinder
if(self.cy == 1):
if ((ti.cast(i, ti.f32) - self.cy_para[0])**2.0 + (ti.cast(j, ti.f32)
- self.cy_para[1])**2.0 <= self.cy_para[2]**2.0):
self.mask[i, j] = 1.0
@ti.func
def to_moment(self, f):
M = ti.Matrix([
[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0],
[-4.0, -1.0, -1.0, -1.0, -1.0, 2.0, 2.0, 2.0, 2.0],
[4.0, -2.0, -2.0, -2.0, -2.0, 1.0, 1.0, 1.0, 1.0],
[0.0, 1.0, 0.0, -1.0, 0.0, 1.0, -1.0, -1.0, 1.0],
[0.0, -2.0, 0.0, 2.0, 0.0, 1.0, -1.0, -1.0, 1.0],
[0.0, 0.0, 1.0, 0.0, -1.0, 1.0, 1.0, -1.0, -1.0],
[0.0, 0.0, -2.0, 0.0, 2.0, 1.0, 1.0, -1.0, -1.0],
[0.0, 1.0, -1.0, 1.0, -1.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 1.0, -1.0, 1.0, -1.0]
])
return M @ f
@ti.func
def from_moment(self, m):
d = ti.Vector([1./9, 1./36, 1./36, 1./6,
1./12, 1./6, 1./12, 1./4, 1./4])
M = ti.Matrix([
[1, -4, 4, 0, 0, 0, 0, 0, 0],
[1, -1, -2, 1, -2, 0, 0, 1, 0],
[1, -1, -2, 0, 0, 1, -2, -1, 0],
[1, -1, -2, -1, 2, 0, 0, 1, 0],
[1, -1, -2, 0, 0, -1, 2, -1, 0],
[1, 2, 1, 1, 1, 1, 1, 0, 1],
[1, 2, 1, -1, -1, 1, 1, 0, -1],
[1, 2, 1, -1, -1, -1, -1, 0, 1],
[1, 2, 1, 1, 1, -1, -1, 0, -1],
])
return M @ (d * m)
@ti.kernel
def do_collide(self, flg: ti.template()): # lbm core equation
for i, j in ti.ndrange((1, self.nx - 1), (1, self.ny - 1)):
feq = ti.Vector(
[self.f_eq(i, j, 0),
self.f_eq(i, j, 1),
self.f_eq(i, j, 2),
self.f_eq(i, j, 3),
self.f_eq(i, j, 4),
self.f_eq(i, j, 5),
self.f_eq(i, j, 6),
self.f_eq(i, j, 7),
self.f_eq(i, j, 8)])
f = self.f_old[i, j]
meq = self.to_moment(feq)
m = self.to_moment(f)
s = ti.Vector([1.0, 1.63, 1.14, 1.0, 1.92, 0.0, 1.92,
self.inv_tau, self.inv_tau])
# MRT
if ti.static(flg == 0):
m += (meq - m) * s
# BGK
else:
m += (meq - m) * self.inv_tau
self.f_old[i, j] = self.from_moment(m)
@ti.kernel
def do_stream(self): # lbm core equation
for i, j in ti.ndrange((1, self.nx - 1), (1, self.ny - 1)):
# inverse index for halfway bounce back
bi = ti.static([0, 3, 4, 1, 2, 7, 8, 5, 6])
for k in ti.static(range(9)):
ip = i - self.e[k, 0]
jp = j - self.e[k, 1]
kk = ti.static(bi[k])
if self.mask[ip, jp] == 0.0:
self.f_new[i, j][k] = self.f_old[ip, jp][k]
else:
self.f_new[i, j][k] = self.f_old[i, j][kk]
@ti.kernel
def update_macro_var(self): # compute rho u v
for i, j in ti.ndrange((1, self.nx - 1), (1, self.ny - 1)):
self.rho[i, j] = 0.0
self.vel[i, j][0] = 0.0
self.vel[i, j][1] = 0.0
for k in ti.static(range(9)):
self.f_old[i, j][k] = self.f_new[i, j][k]
self.rho[i, j] += self.f_new[i, j][k]
self.vel[i, j][0] += (ti.cast(self.e[k, 0], ti.f32) *
self.f_new[i, j][k])
self.vel[i, j][1] += (ti.cast(self.e[k, 1], ti.f32) *
self.f_new[i, j][k])
self.vel[i, j][0] /= self.rho[i, j]
self.vel[i, j][1] /= self.rho[i, j]
@ti.kernel
def apply_bc(self): # impose boundary conditions
# left and right
for j in ti.ndrange(1, self.ny - 1):
# left: dr = 0; ibc = 0; jbc = j; inb = 1; jnb = j
self.apply_bc_core(1, 0, 0, j, 1, j)
# right: dr = 2; ibc = nx-1; jbc = j; inb = nx-2; jnb = j
self.apply_bc_core(1, 2, self.nx - 1, j, self.nx - 2, j)
# top and bottom
for i in ti.ndrange(self.nx):
# top: dr = 1; ibc = i; jbc = ny-1; inb = i; jnb = ny-2
self.apply_bc_core(1, 1, i, self.ny - 1, i, self.ny - 2)
# bottom: dr = 3; ibc = i; jbc = 0; inb = i; jnb = 1
self.apply_bc_core(1, 3, i, 0, i, 1)
# cylindrical obstacle
# Note: for cuda backend, putting 'if statement' inside loops can be much faster!
for i, j in ti.ndrange(self.nx, self.ny):
if (self.cy == 1 and self.mask[i, j] == 1):
self.vel[i, j][0] = 0.0 # velocity is zero at solid boundary
self.vel[i, j][1] = 0.0
inb = 0
jnb = 0
if (ti.cast(i, ti.f32) >= self.cy_para[0]):
inb = i + 1
else:
inb = i - 1
if (ti.cast(j, ti.f32) >= self.cy_para[1]):
jnb = j + 1
else:
jnb = j - 1
self.apply_bc_core(0, 0, i, j, inb, jnb)
@ti.func
def apply_bc_core(self, outer, dr, ibc, jbc, inb, jnb):
if (outer == 1): # handle outer boundary
if (self.bc_type[dr] == 0):
self.vel[ibc, jbc][0] = self.bc_value[dr, 0]
self.vel[ibc, jbc][1] = self.bc_value[dr, 1]
elif (self.bc_type[dr] == 1):
self.vel[ibc, jbc][0] = self.vel[inb, jnb][0]
self.vel[ibc, jbc][1] = self.vel[inb, jnb][1]
self.rho[ibc, jbc] = self.rho[inb, jnb]
for k in ti.static(range(9)):
# self.f_old[ibc,jbc][k] = self.f_eq(ibc,jbc,k) - self.f_eq(inb,jnb,k) + self.f_old[inb,jnb][k]
self.f_old[ibc, jbc][k] = self.f_eq(ibc, jbc, k)
@ti.kernel
def get_display_var(self, flg: ti.template()):
# if (flg == 0): # get velocity magnitude
if ti.static(flg == 0): # get velocity magnitude
for i, j in ti.ndrange(self.nx, self.ny):
self.display_var[i, j] = ti.sqrt(self.vel[i, j][0]**2.0 +
self.vel[i, j][1]**2.0)
# elif (flg == 1): # get x-direction component only
else: # get x-direction component only
for i, j in ti.ndrange(self.nx, self.ny):
self.display_var[i, j] = self.vel[i, j][0]
def solve(self):
gui = ti.GUI('lbm solver', (self.nx, self.ny))
self.init()
for i in range(self.steps):
self.do_collide(0) # 0 for MRT, else for BGK
self.do_stream()
self.update_macro_var()
self.apply_bc()
if (i % 50 == 0):
self.get_display_var(0)
img = cm.plasma(self.display_var.to_numpy() / 0.15 * 2)
gui.set_image(img)
gui.show()
if (i % 1000 == 0):
print('Step: {:}'.format(i))
# ti.imwrite((img[:,:,0:3]*255).astype(np.uint8), 'fig/karman_'+str(i).zfill(6)+'.png')
def pass_to_py(self):
self.get_display_var(1)
return self.display_var.to_numpy()
if __name__ == '__main__':
flow_case = 0
if (flow_case == 0): # von Karman vortex street: Re = U*D/niu = 200
lbm = lbm_solver(401, 101, 0.0001, [0, 0, 1, 0],
[[0.05, 0.0], [0.0, 0.0], [0.0, 0.0], [0.0, 0.0]],
1, [80.0, 50.0, 10.0])
lbm.solve()
elif (flow_case == 1): # lid-driven cavity flow: Re = U*L/niu = 1000
lbm = lbm_solver(256, 256, 0.0255, [0, 0, 0, 0],
[[0.0, 0.0], [0.1, 0.0], [0.0, 0.0], [0.0, 0.0]])
lbm.solve()
# compare with literature results
y_ref, u_ref = np.loadtxt(
'data/ghia1982.dat', unpack=True, skiprows=2, usecols=(0, 2))
fig, axes = plt.subplots(nrows=1, ncols=1, figsize=(4, 3), dpi=200)
axes.plot(np.linspace(0, 1.0, 256), lbm.pass_to_py()
[256 // 2, :] / 0.1, 'b-', label='LBM')
axes.plot(y_ref, u_ref, 'rs', label='Ghia et al. 1982')
axes.legend()
axes.set_xlabel(r'Y')
axes.set_ylabel(r'U')
plt.tight_layout()
plt.show()
8 个赞
作业出圈啦 ![]() ,不知道有没有要过授权
,不知道有没有要过授权 ![]() 。
。
从上至下:层流(非静止画面)、卡门涡街、湍流、方形




(没有授权,就去讹他们一个广告位
3 个赞