timxu5
2020 年7 月 18 日 05:40
#1
in the example mgpcg_advanced,
@ti.kernel
def prolongate(self, l: ti.template()):
for I in ti.grouped(self.z[l]):
self.z[l][I] = self.z[l + 1][I // 2]
which means: z_l = prolongate(z_(l+1)),
I think the code should be like this:
z_l += prolongate(z_(l+1)).
@ti.kernel
def prolongate(self, l: ti.template()):
for I in ti.grouped(self.z[l]):
self.z[l][I] += self.z[l + 1][I // 2]
So I changed the code and the new mgpcg can converge.
I’m very confused which implementation is correct. Why both of them can converge?
1 个赞
Interesting… Does one of them converge faster than the other?
timxu5
2020 年7 月 18 日 16:10
#3
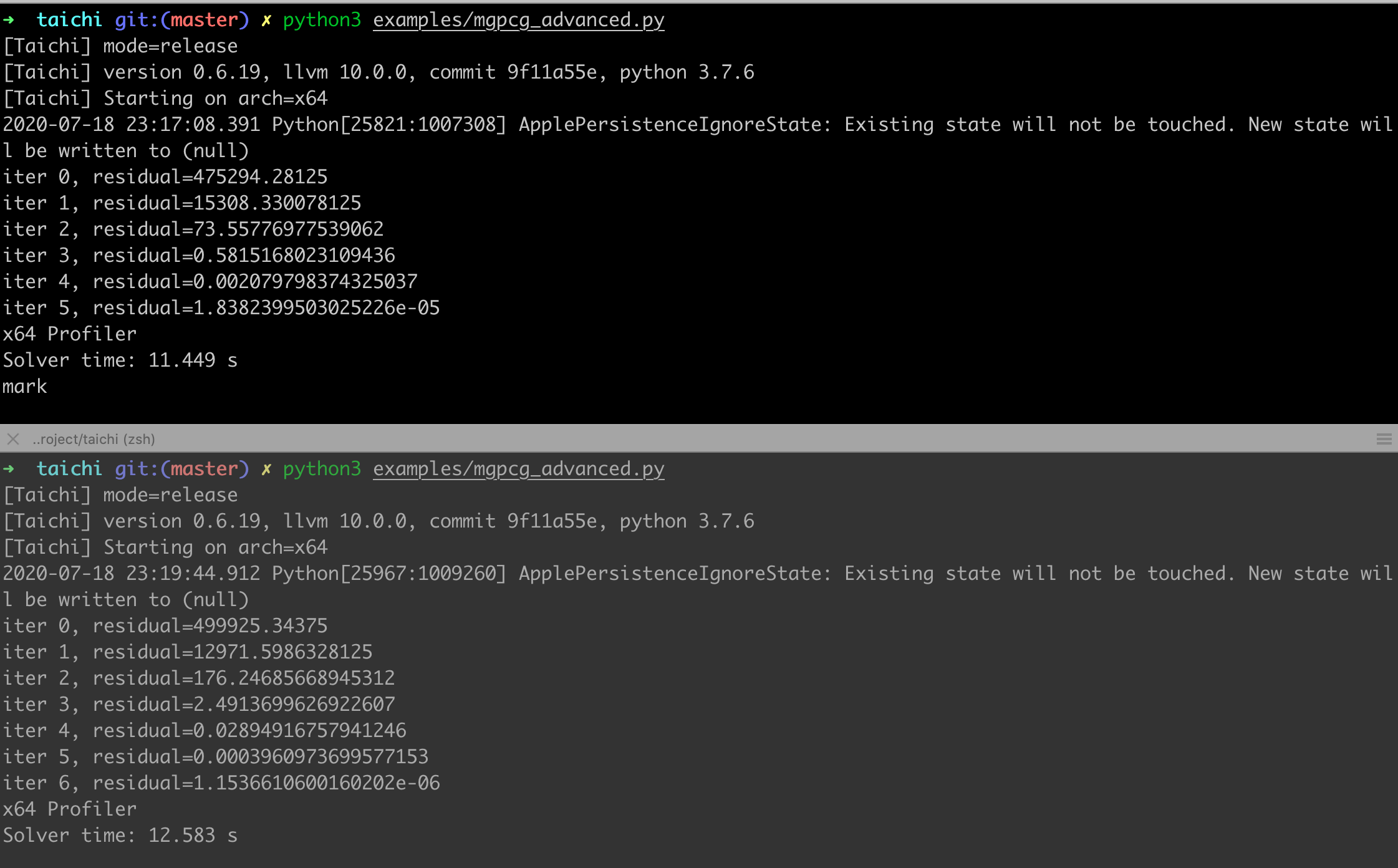
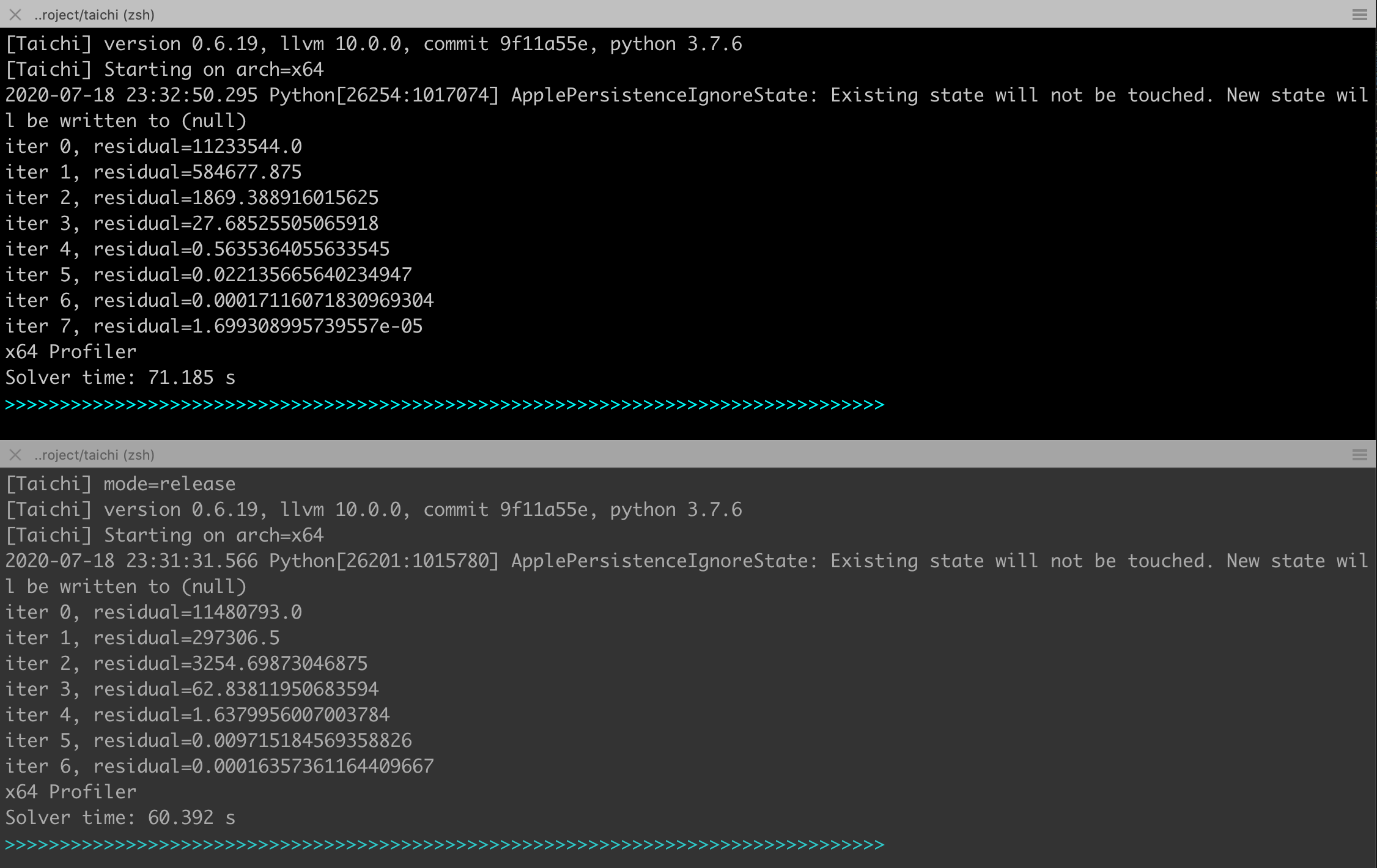
Two versions of them take nearly the same time to converge.
@ti.kernel
def prolongate(self, l: ti.template()):
for I in ti.grouped(self.z[l]):
self.z[l][I] += self.z[l + 1][I // 2]
and the bottom terminal shows the results using code
@ti.kernel
def prolongate(self, l: ti.template()):
for I in ti.grouped(self.z[l]):
self.z[l][I] = self.z[l + 1][I // 2]
When self.N =128, the run time is:
When self.N = 256, the run time is:
While I’m posting the results, I think I can try to explain the reasoning(but all with my imagination).
The paper one is faster for free surface.
BTW, the factor in restrict() should be 1.0 for 2D.